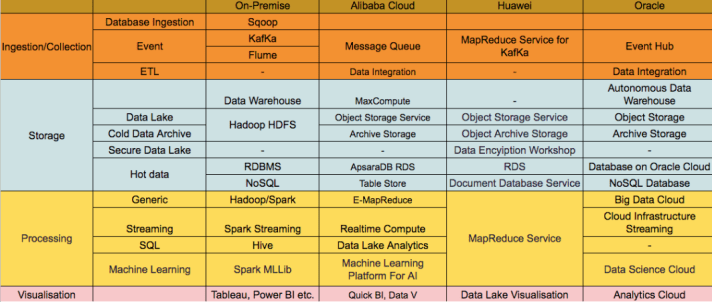
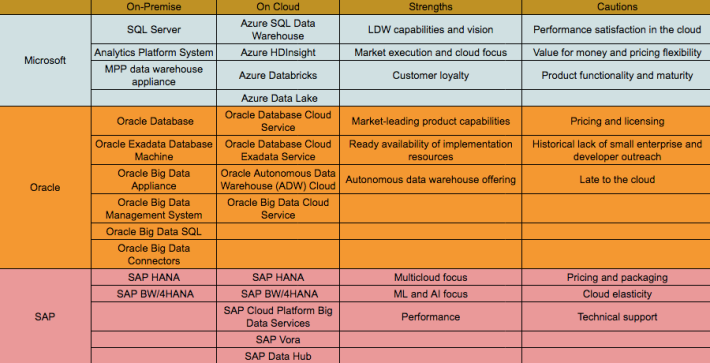
วันก่อนไปบรรยายมีคนถามผมว่าจะติดตั้งระบบ Big Data ในองค์กร ใช้โซลูชั่นของใครดี จะทำเป็นระบบ On-Premise หรือควรใช้ Public Cloud
คงต้องอธิบายว่าระบบ Big Data จะประกอบไปด้วยเทคโนโลยีอยู่ 4 ด้านคือ Data Ingestion/Collection, Data Storage, Data Processing และ Data Visualisation และหลักการทำ Big Data คือเน้นการสร้าง Data Lake ที่เราจะต้องนำข้อมูลดิบที่มีปริมาณมหาศาลมาเก็บไว้ในระยะยาว ซึ่งอาจเป็นข้อมูลธุรกรรมต่างๆ ข้อมูล IoT ซึ่งข้อมูลเหล่านี้มีปริมาณเห็นหลายสิบล้าน หรือจำนวนหลาย TeraByte ทั้งนี้ขึ้นอยู่กับประเภทธุรกิจ บางธุรกิจเช่น Telecom อาจมีบริมาณเป็นหลาย TB ต่อวัน หรือธนาคารก็อาจเป็นจำนวนพันล้านเรคอร์ดต่อปี
การที่ต้องเก็บข้อมูลจำนวนมากและการเก็บข้อมูลต้องพร้อมที่จะประมวลผลในเวลารวดเร็ว จึงเป็นความท้าทายที่ต้องหา Storage ขนาดใหญ่ ซึ่งต้องขยายได้อย่างรวดเร็ว มีราคาถูก และมีความเสถียร ก็เลยเป็นไปได้ยากที่เราจะพัฒนาระบบ Hadoop แบบ On-Premise แล้วในอนาคตต้องขยายระบบไปเรื่อยๆเพื่อจะเก็บข้อมูลทั้งหมด ดังนั้นแนวทางที่ดีคือการเก็บข้อมูลขนาดใหญ่ไว้บน Public Cloud Storage ที่จะตอบโจทย์เหลือราคาความเสถียรและขนาดการเก็บได้ดีกว่า เช่นการใช้ Amazon S3, Azure Data Lake Storage (ADLS) และ Google Cloud Storage เป็นต้น แล้วก็นำข้อมูลที่จะเป็นที่อาจมีความสำคัญอย่างมากที่ไม่อยากนำไปเก็บออกนอกองค์กรมาใส่ไว้ใน Storage ของ Hadoop HDFS ที่เราอาจติดตั้งระบบ Cluster ขนาดเหมาะสมไว้ในองค์กร (On-Premise) แต่ไม่จำเป็นต้องเป็นระบบที่ใหญ่มากนัก
ในแง่ของการประมวลผลข้อมูล (Data Processing) เราสามารถที่จะใช้ Hadoop On-Premise มาทำการประมวลโดยผ่านเทคโนโลยีอย่าง Spark, Hive หรือเครื่องมืออื่นๆ แต่ความท้าทายก็อาจจะอยู่ที่เมื่อต้องการประมวลผลข้อมูลที่ใหญ่มากๆเช่น การทำ Machine Learning กับข้อมูลเป็นสิบหรือร้อยล้านเรคอร์ด กรณีนี้เราจำเป็นต้องการระบบ Cluster ที่มี CPU จำนวนมากซึ่งระบบ On-Premise ไม่สามารถจะรองรับได้ จึงอาจต้องใช้ Services ของ Public Cloud เช่น AWS EMR, Google DataProc, Azure HDinsight ที่เราสามารถกำหนด CPU จำนวนมากได้ หรือบางครั้งก็อาจใช้บริการประมวลผลอื่นๆที่มีอยู่บน Public cloud ซึ่งสามารถช่วยในการประมวลผลอย่างรวดเร็วได้อย่างเช่น Google BigQuery, Azure ML, AWS Athena ก็จะยิ่งทำให้ได้ประสิทธิภาพดีขึ้น ข้อสำคัญการประมวลผลแบบนี้ราคาขึ้นอยู่กับการเวลาในการใช้งานซึ่งถูกกว่าติดตั้งระบบ On-Premise ขนาดใหญ่มากๆ
ในด้านการดึงข้อมูลเข้า Storage (Data Ingestion) ก็คงจะต้องพิจารณาว่าต้นทางของข้อมูลอยู่ที่ใดและ Storage อยู่ที่ใด ถ้าข้อมูลที่จะดึงเข้าจำนวนมากอยู่ในองค์กรก็ควรที่จะตั้งระบบแบบ On-Premise หรือ ถ้าอยู่ภายนอกก็อาจใช้ Public cloud service ส่วนการเลือกใช้เครื่องมือด้าน Visualisation ที่อาจต้องมีทั้งสองระบบ โดยระบบ On-Premise ใช้กับการแสดงข้อมูลภายในองค์กรผ่าน Desktop ส่วนกรณีแสดงผลผ่านเว็บหรืออินเตอร์เน็ตอาจพิจารณาใช้ Public cloud โดยรูปที่ 1 ได้สรุปแนวทางการทำ Big Data Platform โดยทาง Hybrid/Multi Cloud ตามที่อธิบายไว้ข้างต้น
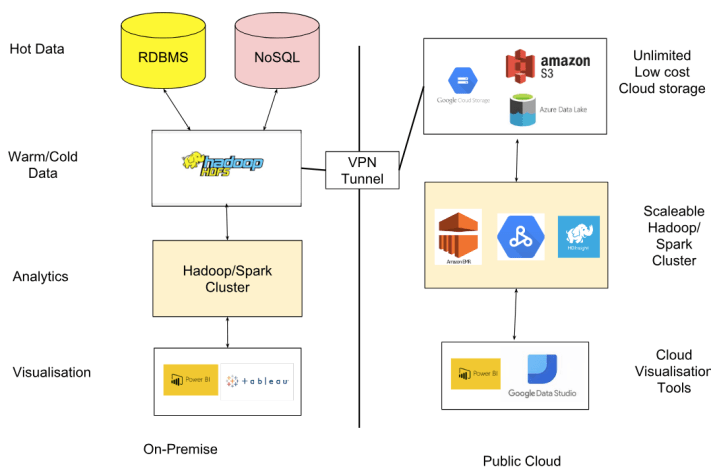
รูปที่ 1 ตัวอย่างระบบ Big Data บน Hybrid/Multi Cloud
แนวทางการติดตั้งระบบ Big Data ที่ดีควรเริ่มจากการทำบน Public Cloud เพื่อความรวดเร็วในการดำเนินงานและลดค่าใช้จ่าย เมื่อเริ่มเห็นผลก็อาจมีการติดตั้งระบบ On-Premise ที่มีขนาดเหมาะสม แล้วมีการ Transfer ข้อมูลไปมากันทั้งสองระบบ โดยเน้นให้ Public cloud เก็บข้อมูลขนาดใหญ่และประมวลผลขนาดใหญ่ ส่วน Hadoop On-Premise เน้นข้อมูลที่สำคัญและต้องการประมวลผลในองค์กร ซึ่งแนวโน้มของผู้ผลิตในระบบ On-Premise ต่างๆเช่น Cloudera หรือ Hortonworks ก็เน้นไปสู่ Hybrid/Multi Cloud ดังแสดงตัวอย่างดังรูปที่ 2
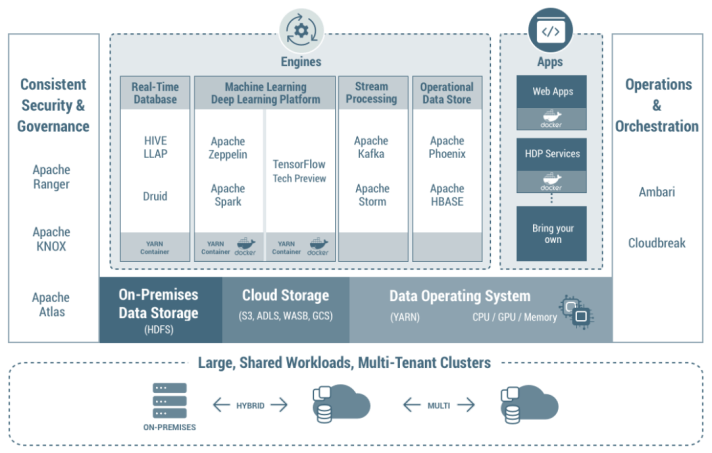
รูปที่ 2 ตัวอย่างโซลูชั่นของ Hortonworks ทีเน้น Multi-Cloud
สุดท้ายผมได้ทำตารางข้างล่างมาเปรียบเทียบระหว่างระบบ On-Premise กับ Public Cloud Service ต่างๆมาให้เพื่อพิจารณาเลือกใช้บริการต่อไป
ธนชาติ นุ่มนนท์
IMC Institute