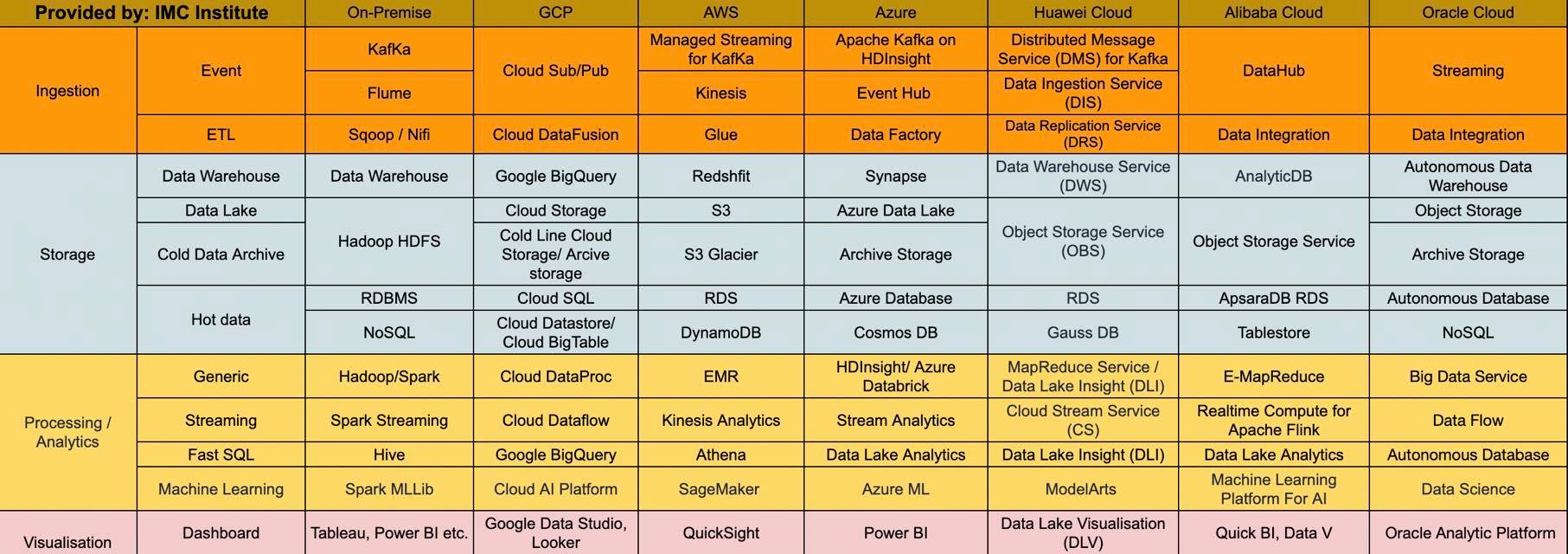
การออกแบบสถาปัตยกรรม Big Data บน Public cloud อาจแตกต่างกับการออกแบบบนระบบ On-premise ที่ผมเคยเขียนไว้ในตอนที่ 1 ว่าไม่ควรเน้นที่จะเป็น Data warehouse (อ่านเพิ่มเติมได้จาก Big Data Architecture #1: Big Data Pipeline ทำไมไม่ใช่ Data Warehouse) ทั้งนี้เนื่องจากเทคโนโลยี Data Warehouse ไม่ได้เหมาะสมกับคุณลักษณะของ Big Dataในเรื่องของ 4V ทำให้การเก็บข้อมูลขนาดใหญ่จะมีราคาแพง และจะเน้นได้เฉพาะข้อมูลแบบ Structure หรือ Semi-structure
แต่ในกรณีของผู้ให้บริการ Public cloud จะมีบริการ Data Warehouse ทีสามารถรองรับข้อมูลขนาดใหญ่ได้ในราคาที่ถูกกว่า ทำให้ในบางกรณีเราสามารถที่จะออกแบบสถาปัตยกรรม Big Data โดยใช้ Data Warehouse as a Service อย่าง Google BigQuery หรือ Azure Synapse ได้ ดังตัวอย่างในรูปที่ 1

กรณีนี้เราจะเห็นการใช้บริการบน Public Cloud สองอย่างหลักๆคือ
- Fully managed ETL service อย่าง Azure Data Factory หรือ Google Cloud DataFusion ที่จะทำหน้าที่ดึงข้อมูลจากแหล่งต่างๆเข่น RDBMS อย่าง MySQL ซึ่งอาจจะอยู่บนระบบ On-Premise หรือ Public Cloud แล้วทำการแปลงข้อมูลให้อยู่ใน Format ที่ต้องการก่อนโหลดเข้า Data Warehouse
- Fully managed data warehouse service อย่าง Azure Synapse หรือ Google BigQuery ซึ่งเป็นบริการแบบ PaaS ที่สามารถรองรับการเก็บข้อมูลขนาดใหญ่ โดยผู้ใช้บริการไม่ต้องไปกังวลเรื่องการดูแลระบบ
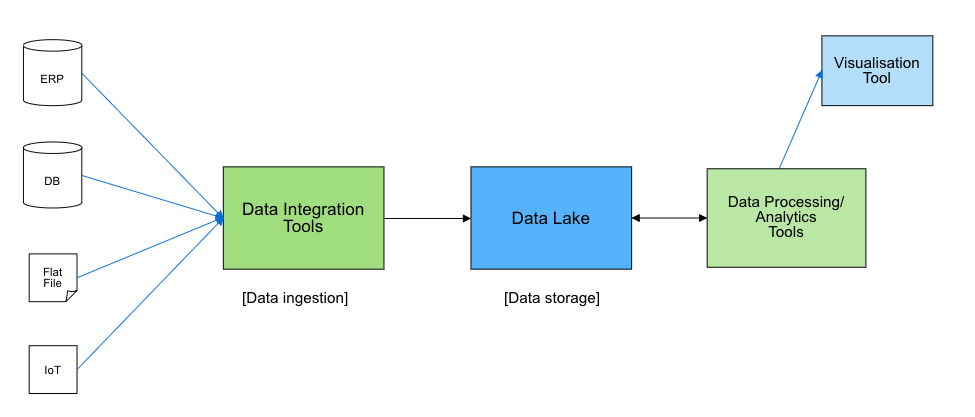
การใช้สถาปัตยกรรม Big Data ที่เน้นเฉพาะ Data Warehouse จะเหมาะกับกรณีของ Big data ที่มีเฉพาะที่มาจากแหล่งข้อมูลแบบ Relational มีรูปแบบข้อมูล (Schema) ที่แน่นอน ไม่ได้มาจากหลายแหล่งข้อมูลนัก และเน้นเฉพาะการทำ Business Intelligence (BI) หรือต้องการสืบค้นข้อมูลในรูปแบบของ SQL แต่หากมีแหล่งข้อมูลจำนวนมากและมีหลากหลายชนิด รวมถึงต้องการทำการวิเคราะห์เชิง Predictive โดยใช้ Machine Learning เราควรที่จะเน้นสถาปัตยกรรมแบบ Data Platform ที่ใช้ทั้ง Data Lake และ Data Warehouse เหมือนกรณีที่ผมเขียนอธิบายไว้ในตอนที่ 2 (อ่านเพิ่มเติมได้จาก Big Data Architecture #2: สถาปัตยกรรมบน Data Lake) ที่มี Block diagram ดังแสดงในรูปที่ 2

ในกรณีการออกแบบสถาปัตยกรรมแบบ Data Platform เราจะเห็นการใช้บริการต่างๆบน Public cloud ดังนี้
- Fully managed ETL service อย่าง Azure Data Factory, Google Cloud Data Fusion หรือ AWS Glue
- Cloud storage อย่าง Azure Data Lake Storage, Google Cloud Storage หรือ AWS S3 เพื่อทำหน้าที่เป็น Storage หลักในการเก็บ Big data
- Fully managed data warehouse service อย่าง Azure Synapse, Google BigQuery หรือ AWS Redshift
- Fully managed Hadoop/Spark service อย่าง Azure HDInsight, Google DataProc หรือ AWS EMR เพื่อที่จะทำหน้าที่ในการทำ Data preparation หรือการทำ Data Analytics อย่าง Machine Learning โดยใช้เทคโนโลยี Hive หรือ Spark
- Ingestion service อย่าง Azure Event Hub, Google Cloud Pub/Sub หรือ AWS Kinesis ที่ทำหน้าที่ในการนำข้อมูลแบบ Streaming เข้าสู่ Cloud Storage
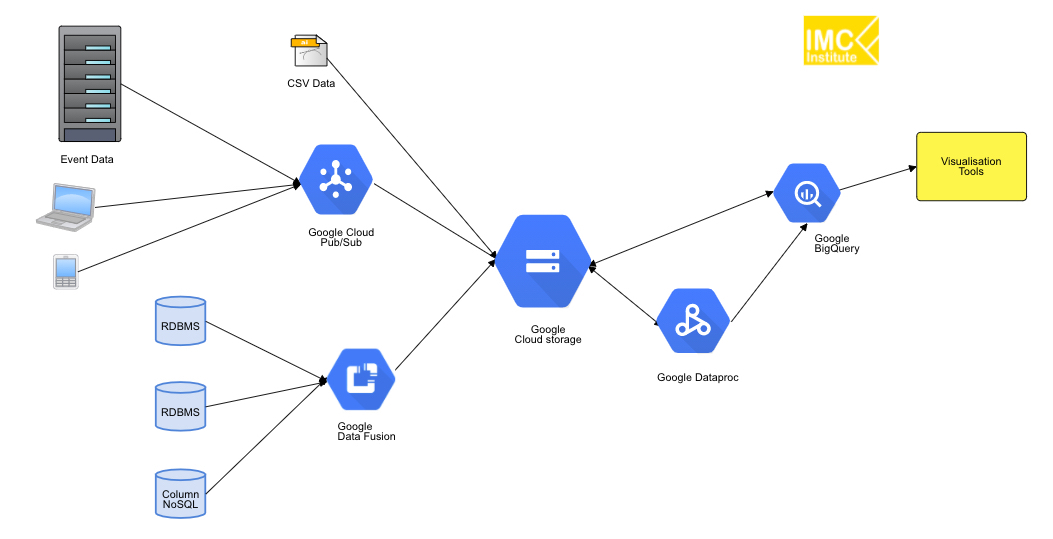
เพื่อให้เห็นสถาปัตยกรรม Big data แบบ Data Platform บน Public cloud services สามรายหลักคือ Microsoft Azure, Google Cloud Platform และ AWS ผมได้วาด Block diagram มาแสดงเปรียบเทียบกับระบบ On-premise ดังรูปที่ 3 – 6



ธนชาติ นุ่มนนท์
IMC Institute