สถาปัตยกรรม Big Data ที่องค์กรต่างๆใช้ในช่วงสิบปีที่ผ่านที่นิยมคือสถาปัตยกรรม Data Lake โดยในระยะแรกจะเป็นระบบ On-Premise ที่ใช้เทคโนโลยี Hadoop โดยใช้ HDFS (Hadoop Distributed File System) เป็น Data Storage แต่ในระยะหลังก็มีการทำสถาปัตยกรรม Data Lake โดยใช้ Public Cloud มากขึ้น อาทิเช่นการใช้ Google Cloud Storage, AWS S3 หรือ Azore Data Lake Storage เนื่องจากมีค่าใช้จ่ายที่ถูกกว่า และสามารถต่อยอดไปกับบริการอื่นๆบน Cloud ได้มากกว่า อาทิเช่น AI as a Service หรือบริการ Data Warehouse บน Cloud
แม้ Data Lake จะสามารถที่จะเก็บข้อมูลได้หลากหลายประเภททั้ง Structure, Semi-Structure และ Unstructure สามารถเก็บข้อมูลจำนวนมหาศาลและมีราคาที่ถูกกว่าการใช้ Data Warehouse แต่การบริหารจัดการข้อมูลบนสถาปัตยกรรม Data Lake ก็มีความท้าทายอยู่ในหลายเรื่อง อาทิเช่น
Governance : เนื่องจากข้อมูลใน Data Lake มีขนาดใหญ่ มีการนำเข้ามาอย่างต่อเนื่อง การบริหารจัดการข้อมูลใน Data Lake จึงทำได้ค้อนข้องยาก ต้องมีระบบการจัดการ Data Catalog ที่ดี ต้องมีการจัดการวงจรชีวิตของข้อมูล(Data Life Cycle) ที่ดี ต้องจัดการเรื่องของความปลอดภัยและความเป็นส่วนตัวของข้อมูลที่ดี
ข้อมูลใน Data Lake ค่อนข้างจะยุ่งเหยิงและขาดความน่าเชื่อถือ เนื่องจากข้อมูลที่ถูกนำเข้าใน Data Lake จะเป็นข้อมูลดิบ และอาจถูกนำเข้าอย่างต่อเนื่องบ่อยครั้ง ทำให้การจัดวางข้อมูลต่างๆค่อนข้างจะยุ่งเหยิง และหากไม่มีการจัดระบบที่ดีพอก็จะกระจัดกระจายไปหมด เหมือนการเก็บข้อมูลใน Harddisk แบบไม่มีระบบ นอกจากนี้ข้อมูลดิบบางครั้งยังขาดความน่าเชื่อถือ ดังนั้นการนำข้อมูลมาใช้ได้ต้องทำ Data Preperation และจัดแบ่งเป็นโซนให้ดีพอ ดังที่ได้เคยอธิบายไว้ในหัวข้อ Big Data Architecture #8: การจัดการข้อมูลบน Data Lake
Data Lake ไม่ได้สนับสนุนข้อมูลที่เป็น Transaction เนื่องจาก Data Lake จะเก็บข้อมูลดิบ จึงไม่ได้สนับสนุนข้อมูลที่เป็น Transaction แบบ Data Warehouse แต่จะมองข้อมูลเป็นออปเจ็คหรือไฟล์ที่จะเป็นก้อนหรือไฟล์เดียวกัน เราจะไม่สามารถเพิ่ม ค้นหาหรือลบข้อมูลระหว่างกลางช่วงใดช่วงหนึ่งได้ และไม่สนับสนุนคุณสมบัติ ACID (atomicity, consistency, isolation, durability) เหมือนที่ Data Warehouse สามารถทำได้กับข้อมูลที่เป็น Transaction
การประมวลผลข้อมูลบน Data Lake ทำได้ยาก ระบบประมวลผลข้อมูลบน Data Lake ไม่ได้ใช้เครื่องมือพื้นฐานเช่นภาษา SQL อย่าง Data Warehouse และบางครั้งแม้แต่การจะประมวลข้อมูลง่ายๆอาจต้องเขียนโปรแกรมที่ซับซ้อนอย่าง Apache Spark หรือ Hive นักวิเคราะห์ข้อมูลบน Data Lake อาจต้องเรียนรู้เทคโนโลยีในการประมวลที่หลากหลาย
ซึ่งผมเองก็เคยได้เขียนบทความในตอนที่แล้วว่า การวิเคราะห์ข้อมูลส่วนใหญ่ด้วยภาษา SQL อาจต้องนำข้อมูลจาก Data Lake เข้าสู่ Data WareHouse เพื่อความรวดเร็วในการแสดงข้อมูล โดยใช้สถาปัตยกรรม Data Lake ร่วมกับ Data Warehouse

ด้วยเหตุผลที่กล่าวมาข้างต้น จึงเริ่มมีการนำสถาปัตยกรรม Big Data ที่เป็น Data Lakehouse เข้ามาใช้โดยเป็นการนำจุดเด่นของทั้ง Data Warehouse และ Data Lake มารวมอยู่ในที่เดียวกัน กล่าวคือสามารถใช้เก็บข้อมูลที่มีโครงสร้างและมีการบริหารจัดการข้อมูลได้เหมือนกับ Data Warehouse แต่จะมีความคล่องตัว ยืดหยุ่นและราคาถูกเหมือนกับ Data Lake ทั้งนี้ Data Lakehouse จะมีคุณสมบัติที่สำคัญดังนี้
- จะสนับสนุนการทำ Transaction เหมือนกับ Data Warehouse และมีคุณสมบัติด้าน ACID
- ข้อมูลจะถูกบังคับให้มี Schema เลยจะทำให้การทำ Governance เป็นไปได้ง่ายขึ้น
- สามารถเก็บข้อมูลได้หลากหลายประเภท ทั้ง Structure, Semi-structure และ Unstructure
- สามารถทำ BI จาก Data Lakehouse ได้โดยตรงผ่าน connector อย่าง JDBC/ODBC
- สนับสนุนเครื่องมือการประมวลผลได้หลากหลายเหมือน Data Lake เช่น SQL หรือ Apache Spark และสามารถที่จะใช้เครื่องมือที่หลากหลายในการที่จะเข้าถึงข้อมูลเช่นการใช้ API หรือภาษาอย่าง Python หรือ R
- มีมาตรฐานเปิดในการเก็บข้อมูล เช่นอาจเป็น Apache Parquet, ORC
- จะต้องแยกระหว่าง Storage กับการประมวลผล (Compute) เพื่อให้แต่ละส่วนสามารถ Scale ได้อย่างอิสระ
ทั้งนี้ในปัจจุบันมีบริการบน Public Cloud หลายๆอย่างที่มีคุณสมบัติใกล้เคียงกับ Data Lakehouse เช่น Amazon Athena, SnowFlake หรือ Google BigQuery แต่ก็อาจขาดคุณสมบัติที่สำคัญในบางเรื่องเช่นด้านการบริหารจัดการ Data Governance หรือไม่สามรถเก็บข้อมูลที่เป็น Unstructure ได้ หรืออย่างกรณีของ Google BigQuery ก็มาตรฐานในการเก็บข้อมูลเฉพาะ
ดังนั้นเวลากล่าวถึง Data Lakehouse จึงทำให้หลายคนจันึกถึงเทคโนโลยีตัวหนึ่งคือการใช้ Delta Lake เสริมไปกับ Apache Spark ที่รันอยู่บน Data Lake แบบเดิม โดย Delta Lake จะเพิ่มคุณสมบัติด้าน ACID กับการสนับสนุนการทำ Transaction ต่างๆตามที่ Data LakeHouse ต้องการ โดยจะมีวิธีการใช้ Delta Lake ได้หลายแบบคือ
- การใช้ Delta Lake ผ่าน local Spark shells
- การใช้ผ่าน GitHub ทาง https://github.com/delta-io/delta
- การใช้บริการ Cloud ของ Databricks ที่เป็น Community Edition
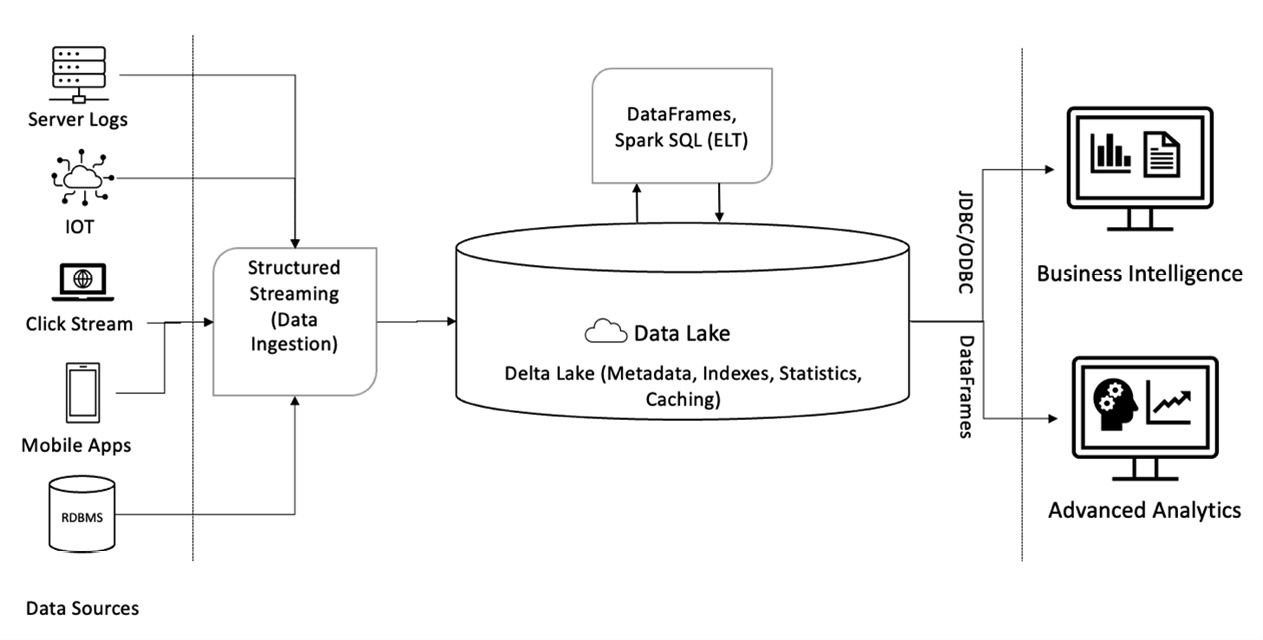
ซึ่งการใช้ Delta Lake เราจะสนใจที่จะใช้กับ Silver Zone ของ Data Lake เพื่อทำให้โซนนั้นทำหน้าที่เป็น Data LakeHouse
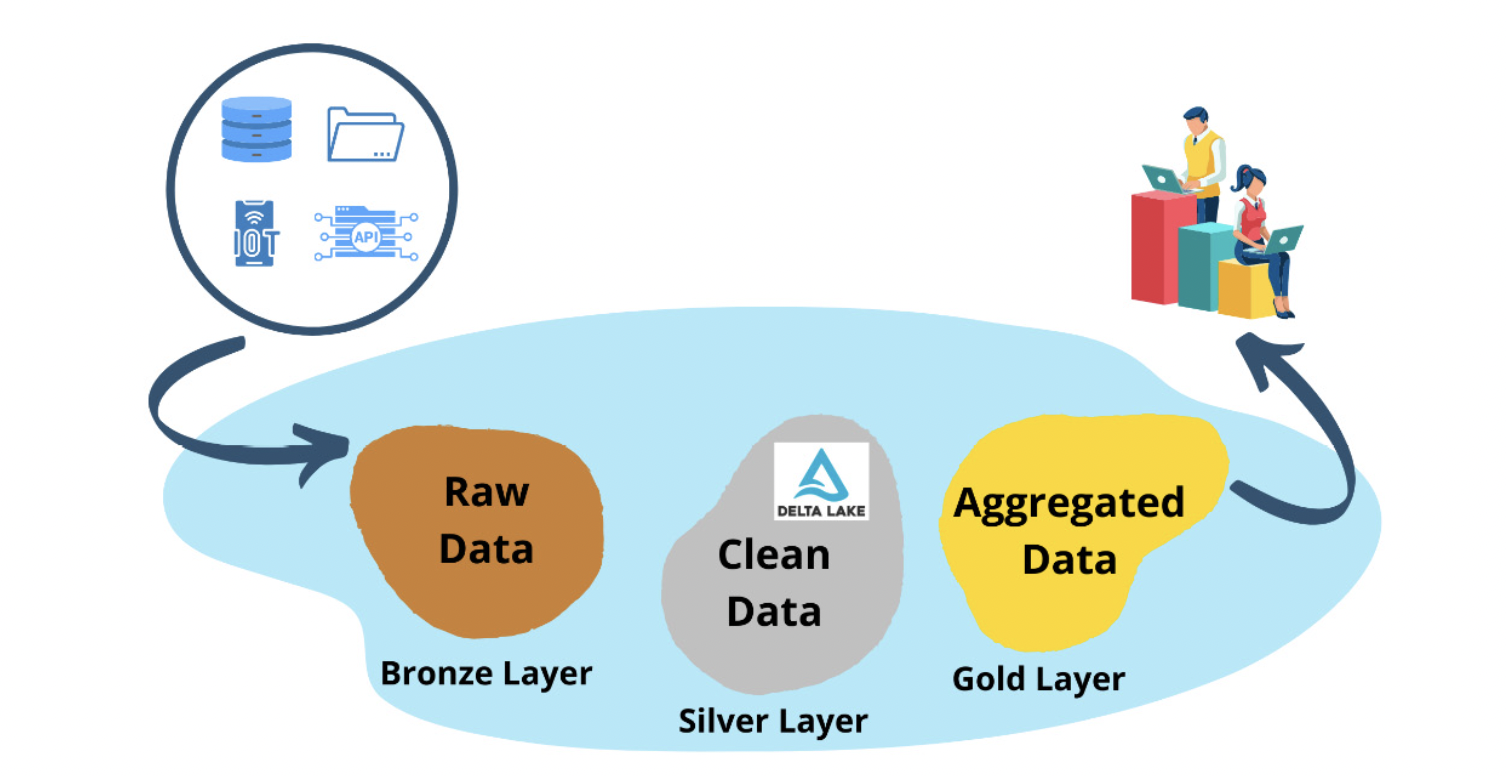
หากท่านใดสนใจที่จะทำ Data LakeHouse ผมแนะนำให้ลองเข้าไปศึกษาเว็บ Databricks เพิ่มเติม
ธนชาติ นุ่มนนท์
IMC Institute
——-
บทความอื่นๆที่เกี่ยวข้อง
- ตอนที่ 1 : Big Data Pipeline ทำไมไม่ใช่ Data Warehouse
- ตอนที่ 2 : สถาปัตยกรรมบน Data Lake
- ตอนที่ 3 : จาก Hadoop แบบ On-Premise สู่การใช้บริการบน Public cloud
- ตอนที่ 4 : สถาปัตยกรรม Data platform บน Public cloud
- ตอนที่ 5 : สถาปัตยกรรม Data platform สำหรับประมวลผลข้อมูลแบบ Streaming
- ตอนที่ 6 : สถาปัตยกรรม Cloud Data platform สำหรับประมวลผลข้อมูลทั้งแบบ Batch และ Streaming
- ตอนที่ 7: แนวโน้มสถาปัตยกรรม Big Data 2022
- ตอนที่ 8: การจัดการข้อมูลบน Data Lake
- ตอนที่ 9: สถาปัตยกรรม Data Lake + Data Warehouse
