วันก่อน ผมร่วมบรรยายงาน Webinar ของสถาบันไอเอ็มซีในหัวข้อเรื่อง “Data Lake / Data Warehouse / Data Lakehouse เอ้าท์แล้วจริงหรือ !? อะไรคือแนวทางถัดไป ?” ร่วมกับคุณฐิติธร เสมาเงิน ตำแหน่ง Solution Engineering Director ของบริษัท Oracle Corporation (Thailand) โดยมีอาจารย์พันธุ์ทิตต์ สิรภพธาดา เป็นผู้ดำเนินการ
ประเด็นที่เราคุยกัน คือเล่าถึงเรื่องของการทำ Big Data ว่า หลายๆองค์กรมักจะเอาเทคโนโลยีเป็นการนำ โดยอาจไม่ได้คิดถึงความต้องการที่แท้จริง ลงทุนไปกับเครื่องมือมากมาย และข้อสำคัญบางครั้งก็เป็นเรื่องที่บริษัทเทคโนโลยีมักสร้าง Buzz word ใหม่ๆขึ้นมาเพื่อสร้างกระแส เช่นมีคำว่า Data Lake หรือ Data Lakehouse แล้วเราก็เห่อตาม ทั้งๆที่บางครั้งโจทย์ในองค์กรเราก็อาจเป็นแค่การทำ Dashboard ง่ายๆให้เข้าใจธุรกิจและข้อมูลต่างๆ ข้อมูลก็อาจไม่ได้มีขนาดใหญ่มากมายนัก และบางทีเราก็อาจไม่ได้ต้องการดูรายงานของข้อมูลแบบทันทีทันใด หลายๆองค์กรรายงานของข้อมูลอาจจะล่าช้า เป็นชั่วโมง เป็นวัน หรือเป็นเดือน ก็เพียงพอต่อกันตัดสินใจ
เรามักจะเอาความสามารถของบริษัทเทคโนโลยีขนาดใหญ่อย่าง Google Facebook หรือ Amazon มา แล้วคิดว่าเราจะต้องทำ Big data ให้เป็นแบบเขา ทั้งๆที่บริษัทเหล่านั้นข้อมูลมหาศาล มีงบประมาณมากมาย และมีบุคลากรมากพอที่จะทำข้อมูลให้เห็นเป็นแบบทันทีทันใด สามารถจะทำการวิเคราะห์ข้อมูล และคาดการณ์ต่างๆได้มากมาย ซึ่งคงแตกต่างกับสิ่งที่องค์กรในบ้านเราจะทำได้
และเมื่อพูดถึงเทคโนโลยี ถ้าเรามองย้อนไปเมื่อ10 กว่าปีก่อน เทคโนโลยี storage มีราคาแพง ประสิทธิภาพของฮาร์ดแวร์ก็ไม่ดีเทียบเท่าปัจจุบัน ดังนั้นในตอนนั้น Data Warehouse จึงทำ Big data ไม่ได้ ไม่สามารถเก็บข้อมูลขนาดใหญ่ในราคาถูกได้ ไม่สามารถเก็บข้อมูลที่เป็น unsturucture ได้ และ Data warehouse ส่วนใหญ่ เหมาะกับการทำ SQL ไม่เหมาะกับงาน Data science
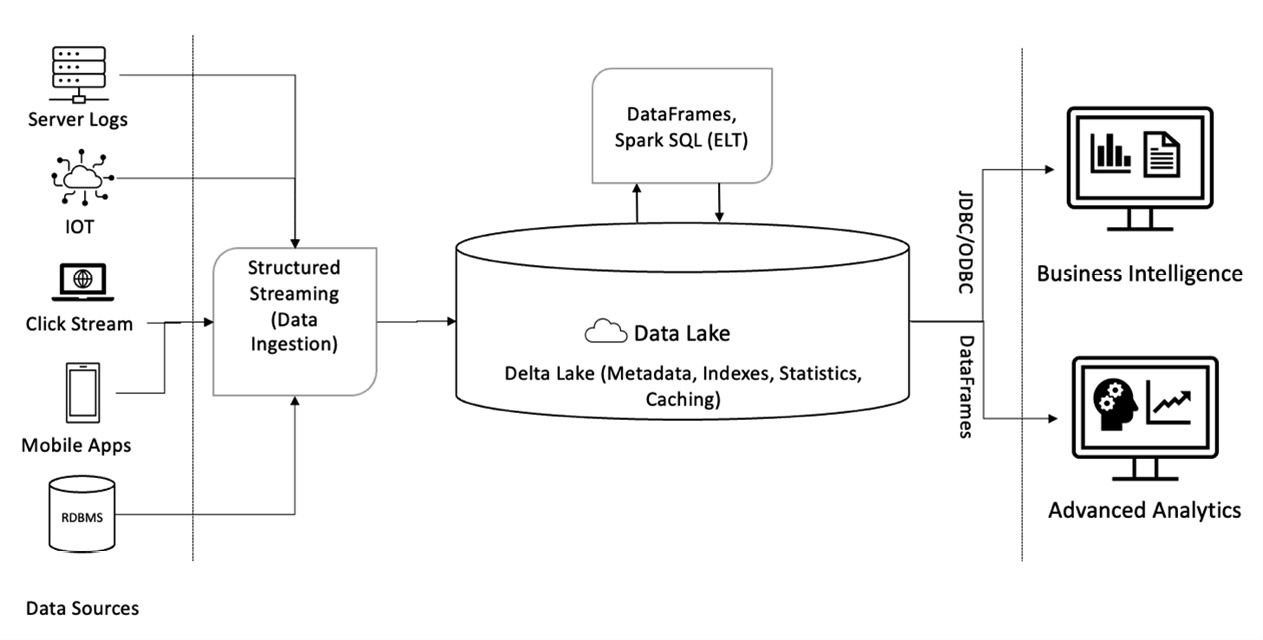
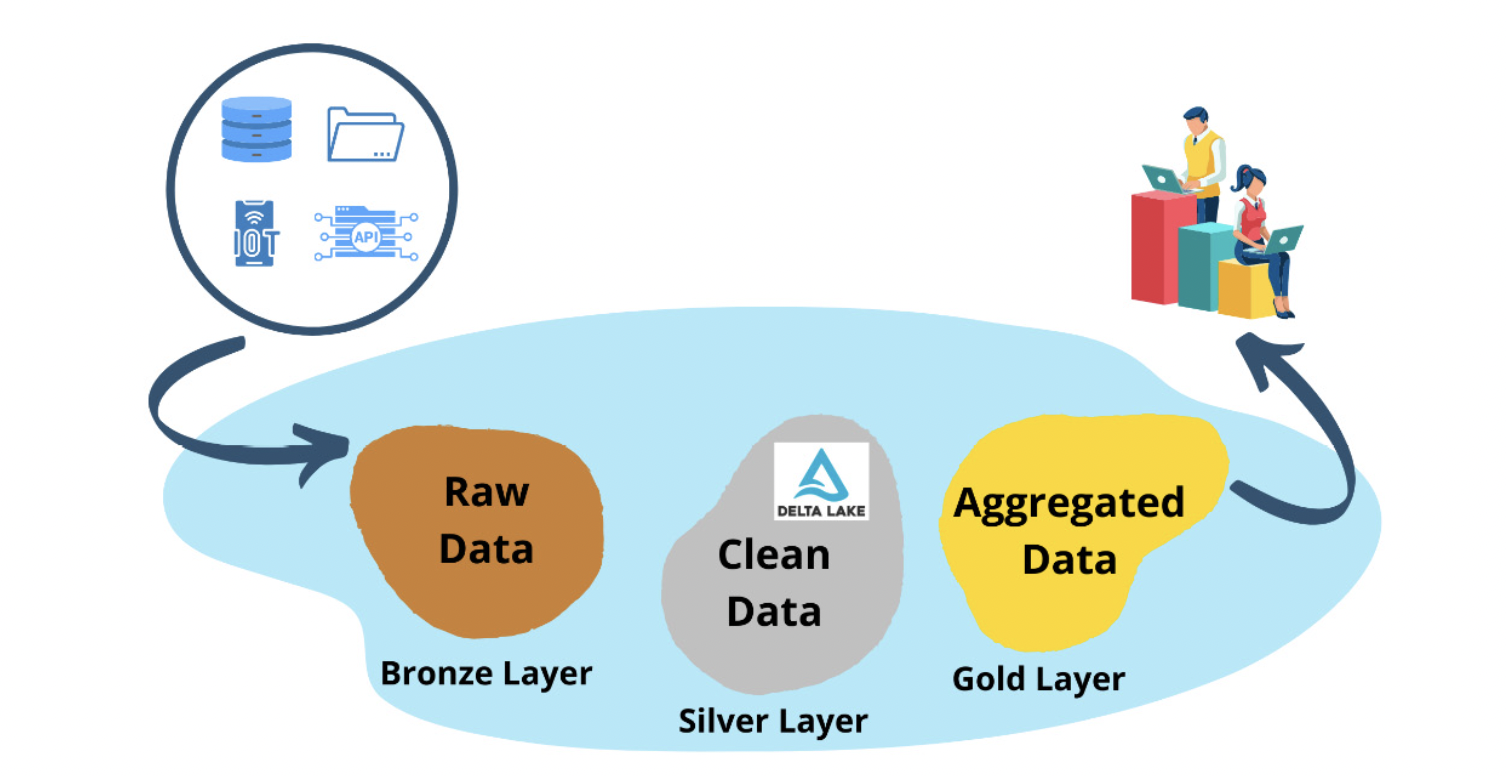
ตอนนั้นเทคโนโลยี Big data จึงเป็นเรื่องของ Data Lake ที่จะมาแทนที่ Data Warehouse และก็มีการนำเทคโนโลยี Hadoop เข้ามาใช้ มีการใช้เครื่องมืออย่าง Apache Spark ในการทำ Data preparation หรือ Data Science แต่การลงทุน Data Lake มีค่าใช้จ่ายค่อนข้างสูง และ เมื่อคำนึงถึง ROI (Return of Investment) กว่าจะคุ้มค่าก็ต้องมีข้อมูลหลายสิบเทราไบต์ (Terabyte) ซึ่งทำให้องค์กรส่วนใหญ่พบว่าไม่คุ้มค่ากับการลงทุนในการทำ Data lake
นอกจากนี้การใช้ Data lake ตามลำพังก็ไม่เหมาะกับองค์กรที่ต้องทำ Business Intelligence จึงต้องนำ Data Warehouse มาช่วยในการทำ Dashboard หลังๆ Buzz word ก็เลยกลายเป็น Data Lakehouse โดยการเพิ่มประสิทธิภาพทำให้ Data Lake กลายเป็น Data Warehouse ได้ แต่ก็ทำได้ค่อนข้างยาก
แต่ด้วยความสามารถของเทคโนโลยีในปัจจุบัน Storage มีราคาถูกลง CPU มีความเร็วขึ้น จึงทำให้ Data Warehouse สามารถเก็บข้อมูลขนาดใหญ่หลายสิบเทราไบต์ได้ในราคาถูกลง แถมเก็บ unstructure data ได้ ทำ Data science ได้ แถมสมัยนี้ SQL ยังทำ Data science ได้ การเขียน code จึงง่ายขึ้น ดังนั้นความจำเป็นในการใช้ Hadoop หรือ Spark ก็เริ่มน้อยลง และการลงทุนกับ Data Warehouse ในการทำ Big data อาจจะคุ้มค่ากว่าถ้าข้อมูลไม่ได้ใหญ่มากมายมหาศาล
นอกจากนี้บริการบน Public Cloud หลายอย่าง ก็สามารถนำ Data Warehouse มาทำ Big data ได้ เช่น Google cloud platform มีบริการอย่าง BigQuery ที่เป็น Data Warehouse ขนาดใหญ่ ที่เก็บข้อมูลได้ทุกประเภท (Structure, semi-structure และ unstructure) แถมทำ Machine learning โดยใช้ SQL อย่างง่ายๆได้ กล่าวคือ Google Cloud กำลังทำ Data Warehouse ให้กลายเป็น Data Lakehouse ได้ โดยไม่ต้องใช้ Hadoop หรือ Spark ที่ต้องทำ Data Lake ให้เป็น Data Lakehouse ซึ่งทำได้ยากกว่า
เรายังได้คุยกันว่า Buzz word ใหม่ๆอย่าง Data Fabric ที่บอกว่า Data อาจเก็บไว้ที่ไหนก็ได้ และประมวลผลที่ไหนก็ได้ ตามทฤษฎีอาจจะใช่ แต่สุดท้ายในทางปฎิบัติคงจะทำได้ยากเพราะเราต้องคำนึงถึง Data gravity หรือแรงดึงดูดของข้อมูล ถ้าข้อมูลเราอยู่ที่ใด เราควรจะต้องประมวลผลที่นั้นเป็นส่วนใหญ่ เพื่อลดค่าใช้จ่ายในการประมวลผลข้ามแพลตฟอร์ม หรือลดความล่าช้าในการถ่ายโอนข้อมูลข้ามแพลตฟอร์ม
สุดท้ายผมปิดท้ายเล่าให้ฟังว่า สิบกว่าปีก่อนพอ Data lake มาใหม่ๆ ผมก็ใช้เวลาในการเรียน การสอน การทำ Big data บน Hadoop และ Spark พอ Big data บน Public Cloud มาก็เริ่มมาใช้ Cloud storage เป็น Data Lake แทน Hadoop และใช้ Spark as a Service แต่พอเทคโนโลยีปัจจุบันมีประสิทธิภาพมากยิ่งขึ้น ก็สามารถกลับมาใช้ Data Warehouse ใช้ SQL ทำโครงการ Big data ได้เหมือนสมัยที่ทำข้อมูลบน Database ธรรมดาเมื่อสิยกว่าปีก่อน
ดังนั้นก่อนจะก้าวไปทำเทคโนโลยีตาม Buzz word เราควรจะเข้าใจวัตถุประสงค์และความต้องการของธุรกิจเราให้ชัดเจนก่อน และก็อาจไม่จำเป็นต้องตามเทคโนโลยีไปตลอด อย่างกรณีนี้สุดท้ายไปๆมาๆก็กลับกลายเป็นว่า Datawarehouse ก็กลายเป็น Data Lakehouse ที่ทำโครงการ Big data ได้อย่างง่าย
ธนชาติ นุ่มนนท์
IMC Institute
(ผู้สนใจสามารถติดตาม Webinar ได้ตาม Link นี้)