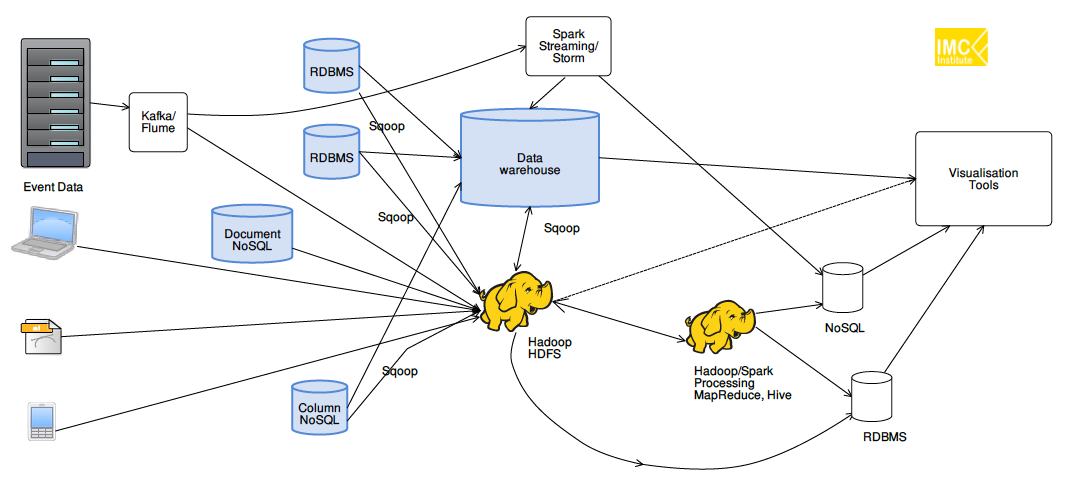
สถาปัตยกรรม Data platform ที่ผมได้อธิบายในตอนที่ผ่านๆมาออกมาเน้นที่การประมวลผลแบบ Batch แม้ข้อมูลที่นำเข้ามาจะสองประเภทคือทั้งแบบ Batch และ Streaming แต่ข้อมูลทั้งสองประเภทจะถูกนำมาเก็บใน Storage ชุดเดียวกันที่ทำหน้าที่เป็น Data Lake แล้วนำไปประมวลผลและวิเคราะห์ข้อมูลในลักษณะที่เป็นแบบ Batch เท่านั้น
ในกรณีที่เราต้องการจะประมวลผลข้อมูล streaming แบบ real-time หรือ Near real time ได้นั้น รูปแบบสถาปัตยกรรมที่ผ่านมาอาจไม่สามารถตอบโจทย์ได้ ดังนั้นจึงจำเป็นจะต้องออกแบบสถาปัตยกรรมในรูปแบบอื่น ซึ่งโดยทั่วไปจะมีอยู่สองรูปแบบคือ Lambda architecture และ Kappa architecture
- Lambda architecture จะเป็นสถาปัตยกรรมดังรูปที่ 1 ที่แบ่งออกเป็น 3 Layer คือ Batch layer ที่จะเป็นการประมวลผลข้อมูลแบบ Batch ที่อยู่ใน Data Lake โดยมี Speed layer ที่จะเป็นการประมวลผลข้อมูล Streaming แบบ Realtime และ สุดท้ายจะเอาผลลัพธ์ของการประมวลผลทั้งสองมารวบรวมไว้ที่ Serving layer เพื่อนำมาแสดงผลต่อไป
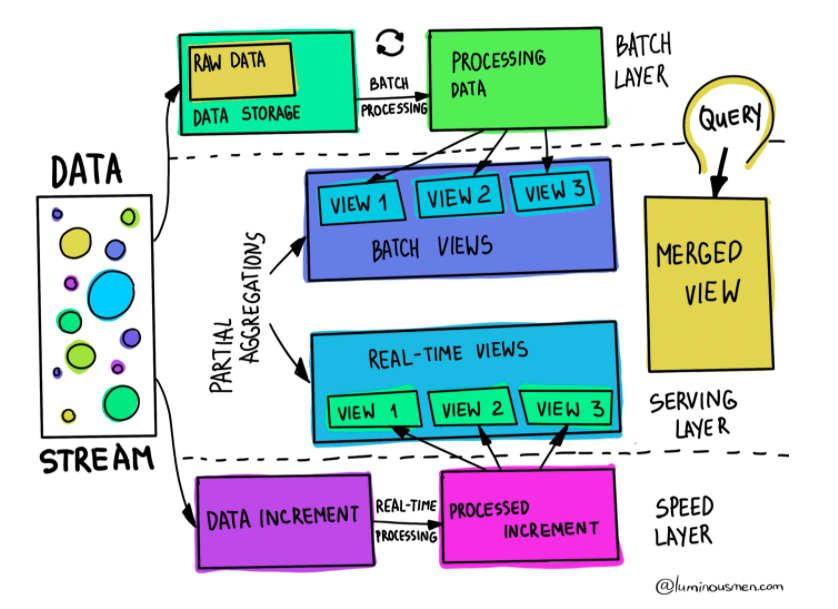
- Kappa architecture จะเป็นสถาปัตยกรรมดังรูปที่ 2 ที่มีเพียง 2 Layer Ffpจะมองข้อมูลทุกประเภทเป็นแบบ Streaming แม้แต่ข้อมูลในอดีตที่เป็นแบบ Batch ก็จะถูกป้อนเข้ามาแบบ Streaming แล้วประมวลผลไว้ที่ Speed layer จากนั้นจึงเก็บผลลัพธ์ไว้ที่ Serving layer จุดเด่นของการใช้สถาปัตยกรรมแบบนี้คือเราสามารถเขียนโปรแกรมทั้งหมดได้ใน Speed layer ไม่จำเป็นต้องแยกโปรแกรมออกมาสองชุดแบบสถาปัตยกรรม Lambda

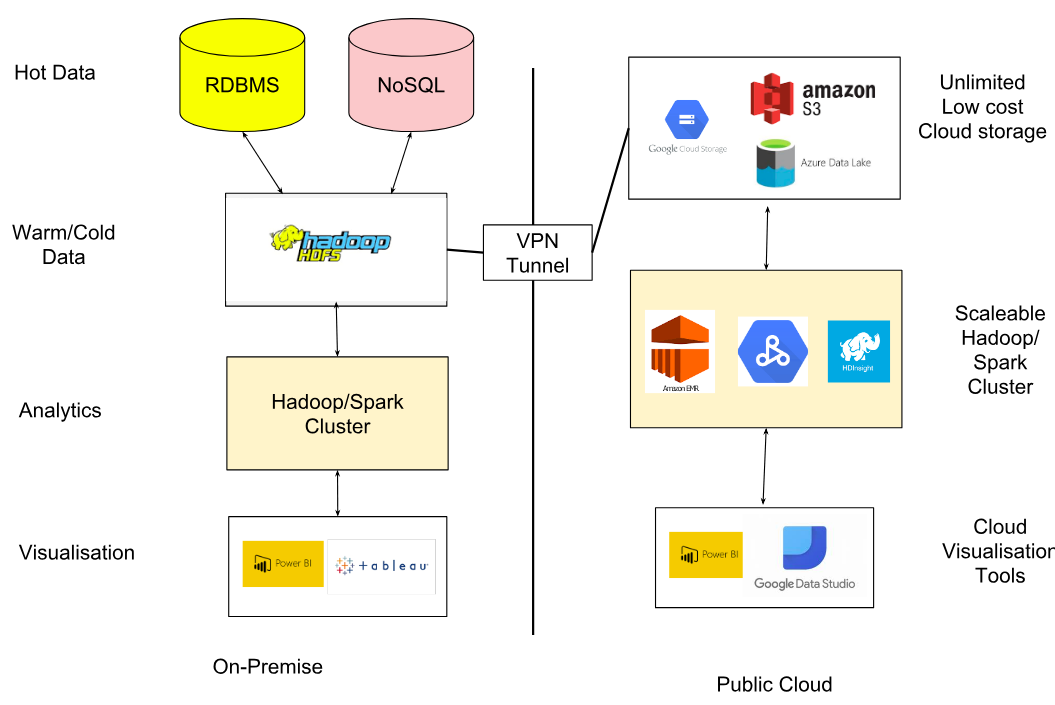
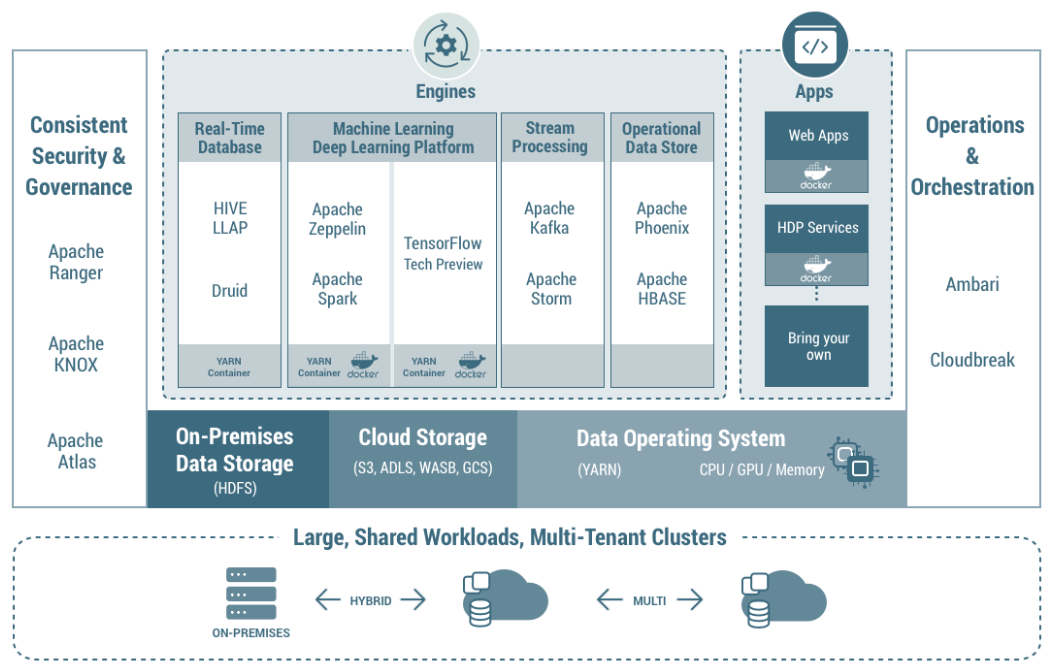
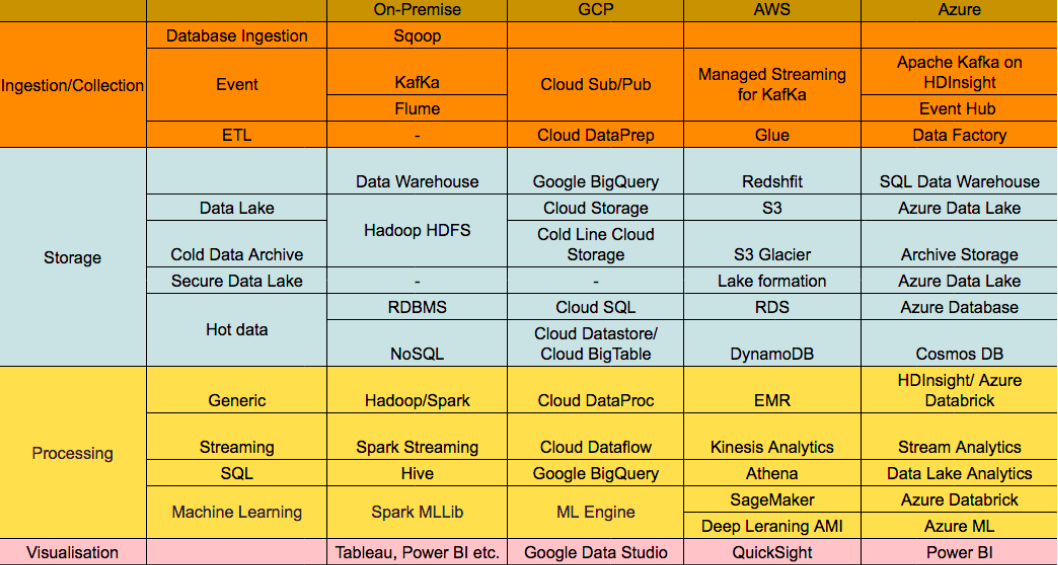
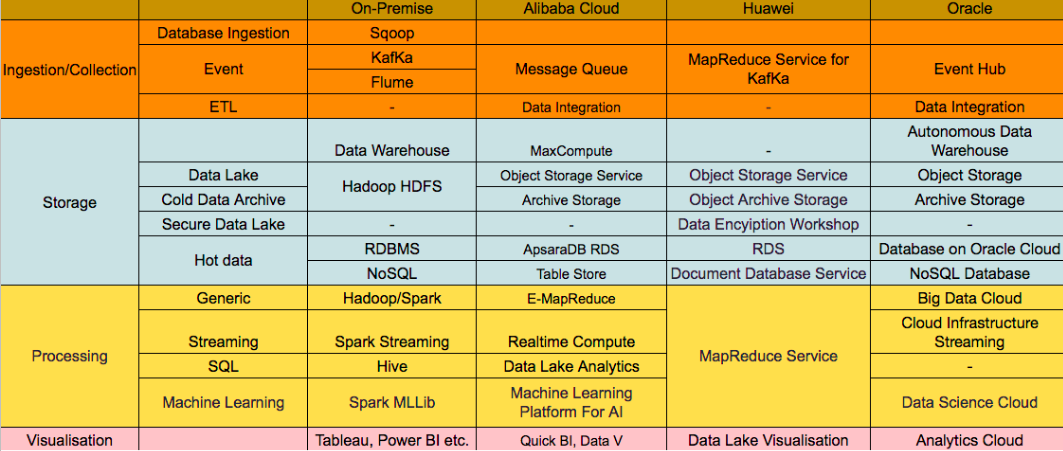
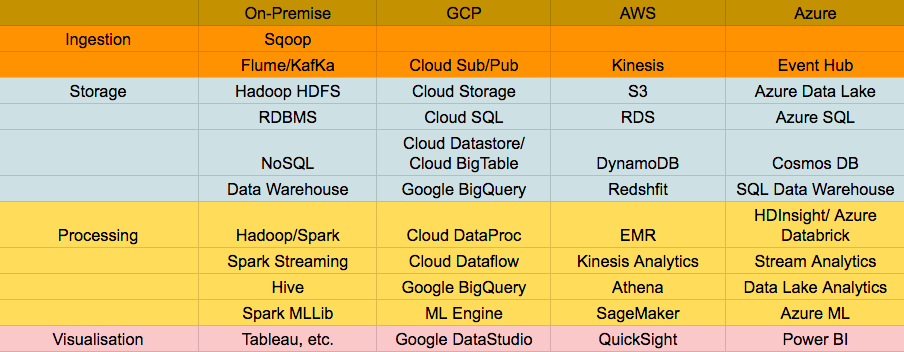
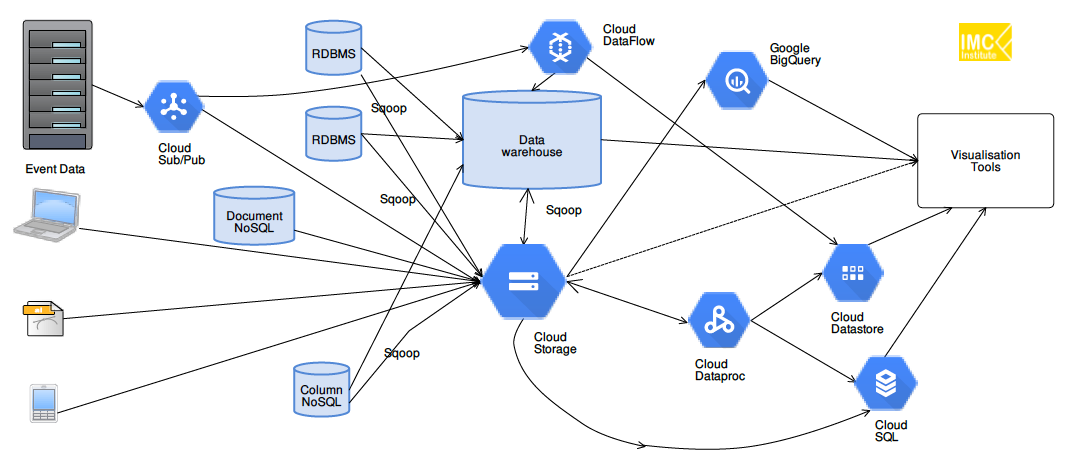
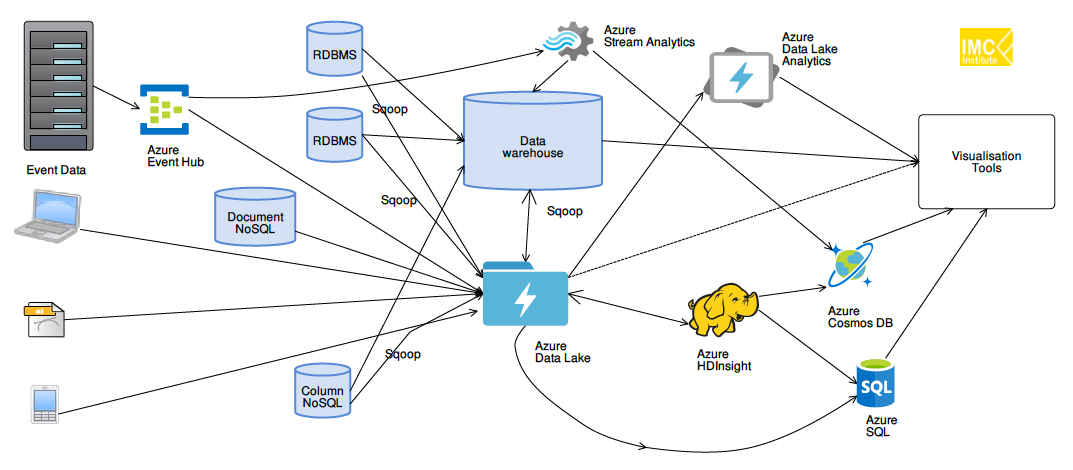
ทั้งนี้เทคโนโลยีที่จะนำมาใช้ในกy[สถาปัตยกรรมทั้งสองแบบนี้ในระบบ On-premise โดยทั่วไปมักจะเป็นเทคโนโลยี Hadoop และ Kafka ดังแสดงในรูปที่ 3

โดยเราสามารถที่จะเลือกใช้เทคโนโลยีต่างๆในแต่ละ Layer ได้ดังนี้
- Batch Layer: ข้อมูล Streaming ที่เข้ามาอาจดึงเข้ามาด้วย KafKa แล้วเก็บไว้ใน Data Lake อย่าง HDFS และประมวลผลด้วย Hive, Spark
- Speed Layer: ข้อมูล Streaming ที่เข้ามาอาจดึงเข้ามาด้วย KafKa แล้วเก็บไว้ใน Fast Storage อย่าง KafKa storage และประมวลผลแบบ Realtime ด้วย Spark Streaming, KafKa Streaming, KSQL
- Serving Layer: ผลลัพธ์ของการประมวลในแต่ละ Layer อาจนำมาเก็บใน Data Warehouse ที่อาจเป็น NoSQL หรือ RDBMS อย่าง Cassandra, HBase, Oracle, MySQl
ทั้งนี้ในกรณีของ Lambda architecture ก็จะเน้นใช้เทคโนโลยีทั้งหมดในรูป แต่กรณีของ Kappa architecture จะไม่บล็อกของการประมวลผลแบบ Batch แต่จะป้อนข้อมูลดิบจาก Data Lake ไปประมวลผลผ่าน Fast storage และ Realtime processong/analytics
ธนชาติ นุ่มนนท์
IMC institute


 รูปที่ 1 องค์ประกอบของสถาปัตยกรรมระบบ Big Data
รูปที่ 1 องค์ประกอบของสถาปัตยกรรมระบบ Big Data รูปที่ 2 ตัวอย่างเทคโนโลยีด้าน Big Data
รูปที่ 2 ตัวอย่างเทคโนโลยีด้าน Big Data