ช่วงนี้ทุกภาคส่วนในประเทศเราจะพูดถึงเทคโนโลยี Big Data บ่อยมาก บางครั้งก็บอกว่าหน่วยงานตัวเองกำลังทำ Big Data บ้างก็บอกว่าเก็บข้อมูลเป็น Big Data บ้างก็บอกว่าต้องวิเคราะห์ข้อมูลโดยใช้ Big Data ผมว่าผู้บริหารบ้านเราเล่นกับเทอม Big Data มากเกินไป โดยไม่เข้าใจความหมายที่แท้จริง และส่วนมากไม่ได้นำมาใช้ประโยชน์อย่างแท้จริง กลายเป็นว่าใช้ข้อมูลเล็กน้อยเพียงผิวเผินและไม่สนใจที่จะศึกษาความหมาย การใช้ Big Data อย่างแท้จริงเลยทำให้บ้างครั้งบ้านเราสูญเสียโอกาสไปอย่างมาก ก็เพียงเพราะว่าเราต้องการแค่สร้างภาพและตอบโจทย์เพียงแค่ว่า ฉันได้ทำ Big Data แล้วทั้งๆที่ก็อาจเป็นแค่ข้อมูลเล็กๆธรรมดาๆและก็อาจทำรายงาน หรือทำ Business Intelligence สรุปข้อมูลออกมากโดยไม่มีการทำ Analytics วิเคราะห์ข้อมูลขนาดใหญ่เพื่อสร้างศักยภาพการแข่งขันให้หน่วยงานแต่อย่างใด
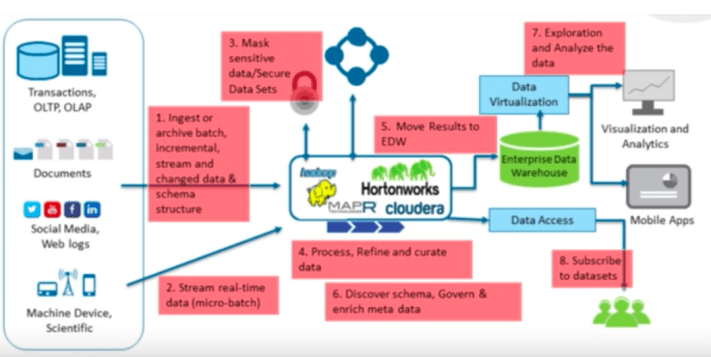
ผมคงไม่อธิบายความหมายของ Big Data มากนัก เพราะตัวเองก็เคยเขียนแนะนำความหมายมาหลายๆครั้ง ไม่ว่าจะเป็น 3Vs อย่าง Volume, Velocity และ Variety หรือเราจะเพิ่มเรื่องของ Varacity เข้าไปอีก โดยถ้าสนใจจะลองดูความหมายก็อาจกลับไปอ่านบทความเก่าๆของผมได้ที่ Big Data และเทคโนโลยี Hadoop กับการพัฒนาองค์กรด้านการวิเคราะห์ข้อมูล และผมก็เคยพยายามจะชี้ให้เห็นว่าถ้าเรามองถึง Big Data เรามักจะเห็นข้อมูลอยู่สี่ประเภทดังรูปที่ 1 ก็คือ
- Social media data
- Mobile data
- Internet of things data
- Transactional data

รูปที่ 1 ประเภทข้อมูลของ Big Data
(อ่านรายละเอียดเพิ่มเติมได้ในบทความ การวิเคราะห์พฤติกรรมลูกค้าควรมีข้อมูลธุรกรรมขนาดใหญ่ของลูกค้าแต่ละราย)
คุณลักษณะที่สำคัญสุดประการหนึ่งของข้อมูลแบบ Big Data คือต้องมี Velocity เข้ามา การจะวิเคราะห์ข้อมูลขนาดใหญ่ได้ดีและมีความแม่นยำขึ้นต้องมีข้อมูลที่เข้ามาอย่างต่อเนื่องและทันสมัย อาทิเช่นถ้ามีข้อมูล CRM ที่เก็บย้อนหลังไว้นานๆ แม้จะมีจำนวนลูกค้าเป็นล้านแต่ก็อาจจะไม่ทันสมัยเพราะข้อมูลลูกค้าก็อาจไม่ถูก update เช่นเบอร์โทรศัพท์ ที่อยู่ อาชีพ หรือแม้แต่ชื่อก็อาจเปลี่ยนไป แต่ในทางตรงข้ามถ้าเรามีข้อมูลธุรกรรมที่เข้ามาอย่างต่อเนื่องเช่นข้อมูลมาซื้อสินค้ากับเรา เราจะเข้าใจข้อมูลลูกค้ามากขึ้น อาจเห็นพฤติกรรมของเขาไว้ไปสาขาไหนอยู่ที่ใด ดังนั้นผมเลยเคยเขียนบอกไว้ว่า หลักการสำคัญของ Big Data Analytics ก็คือการที่เราสามารถเก็บข้อมูล Transactional data ให้มากที่สุดและมีรายละเอียดมากที่สุดเท่าที่ทำได้ (อ่านรายละเอียดเพิ่มเติมได้ในบทความ Big data ต้องเริ่มต้นจากการวิเคราะห์ Transactional data ไม่ใช่เล่นกับ summary data)
ดังนั้นถ้าเราต้องการจะสร้างศักยภาพการแข่งขันขององค์กรด้วย Big Data เราคงต้องวางกลยุทธ์ให้องค์กรมีข้อมูลในสี่ประเภทที่ผมกล่าวไว้ข้างต้น แต่คำถามที่ท้าท้ายก็คือว่าเราจะหาข้อมูลเหล่านั้นมาได้อย่างไร ซึ่งหากเราสามารถทำได้ก็จะทำ Big Data Analytics ที่แท้จริงได้ เมื่อวานนี้ผมไปบรรยายให้กระทรวงการท่องเที่ยวและกีฬาและพยายามยกตัวอย่างการใช้ Big Data ในการท่องเที่ยว โดยอาจมีโจทย์ต่างๆที่น่าสนใจดังนี้
- การใช้เพื่อการวางแผนของภาครัฐในการกำหนดนโยบาย กำหนดเส้นทางการท่องเที่ยว หรือแม้แต่การวางแผนการบริการรถสาธารณะ
- การเข้าใจพฤติกรรมการท่องเที่ยว
- การทำ Personalisation ให้นักท่องเที่ยว
ซึ่งจากโจทย์ที่ยกมา ผมก็ชี้ให้เห็นว่าเราไม่สามารถที่จะทำได้โดยได้ข้อมูลแค่จำนวนนักท่องเที่ยวรายวเดือนหรือหรือวันที่เป็นข้อมูลสรุป แต่เราต้องมีข้อมูลต่างๆเช่น
- ข้อมูลจาก Social Media ที่อาจเป็นการ Tag ตำแหน่งที่อยู่ หรือรูปถ่าย จะต้องมีข้อมูลป้อนเข้ามาในแต่ละวินาทีเป็นจำนวนมาก
- ข้อมูลจาก Telecom ที่จะเห็นข้อมูลของนักท่องเที่ยวเป็นวินาทีว่าอยู่ที่ไหน เป็นต้น
- ข้อมูลจาก IoT ที่ในอนาคตอาจมีข้อมูลจาก CCTV ที่เห็นจำนวนนักท่องเที่ยวในแต่ละที่อยู่ตลอดเวลา
- ข้อมูล Transaction เช่นข้อมูลจากการจองโรงแรม ข้อมูลการเดินทางจากสายการบิน การรถไฟ หรือการท่าอากาศยาย ซึ่งข้อมูลเหล่านี้ต้องเป็นข้อมูลดิบที่ให้เห็นเป็นนาที หรือเป็นรายธุรกรรม ไม่ใช่ข้อมูลสรุป
จากข้อมูลเหล่านี้เราก็อาจมาทำการวิเคราะห์ในเรื่องต่างๆได้เช่น
- พฤติกรรมการเดินทางของนักท่องเที่ยวว่าจะเดินทางจากจุดไหนไปยังที่ใดต่อ
- ตำแหน่งไหนมีคนเยี่ยมชมมากน้อยเพียงใด ในช่วงเวลาใด และอนาคตควรทำอย่างไร
- วิธีการเดินทางของนักเที่ยวเช่นมาจุดนี้โดยเครื่องบิน หรือรถไฟ หรือรถยนต์
- การทำ Segementation นักท่องเที่ยวตามอายุ สัญชาติ เป็นต้น
จากที่กล่าวมาทั้งหมดจะเห็นได้ว่าเมื่อพูดถึง Big Data จะไม่ใช่ข้อมูลสรุป แต่จะต้องมีข้อมูลขนาดใหญ่ที่แท้จริงโดยเฉพาะข้อมูลธุรกรรมในการวิเคราะห์ ในปัจจุบันบางอุตสาหกรรมเริ่มมีความน่ากลัวที่ต่างชาติเข้าเก็บข้อมูลธุรกรรมเหล่านี้ไปหมด โดยที่หน่วยงานในประเทศเรากลับไม่ให้ความสำคัญ และไม่เข้าใจว่าข้อมูลเหล่านั้นมีความสำคัญยิ่งในการที่จะทำ Big Data ที่แท้จริง สุดท้ายเราก็จะสูญเสียศักยภาพการแข่งขันไป
ธนชาติ นุ่มนนท์
IMC Institute