ปีที่ผ่านมาทาง IMC Institute ได้เปิดอบรมหลักสูตรทางด้าน Emerging Technology ต่างๆเป็นจำนวนมาก โดยเฉพาะทางด้าน Big Data ได้เปิดหลักสูตรต่างๆทั้งทางด้าน Hadoop, Apache Spark, Business Intellegence, Data Science, Data Visualisation, R Programming และ Machine Learning โดยอบรมคนไปร่วม 1,600 คน นอกจากนี้ก็ยังมีโครงการต่างๆทั้ง การจัดฟรีสัมมนา Big Data User Group การจัดงาน Big Data Challenge ร่วมกับสำนักงานรัฐบาลอิเล็กทรอนิกส์ (องค์การมหาชน) และการจัดอบรม Train the trainer : Big Data Analytics & Machine Learning ให้กับอาจารย์มหาวิทยาลัยต่างๆจำนวน 30 คนในช่วงเดือนกรกฎาคม
โครงการหนึ่งที่จัดให้กับนักศึกษามหาวิทยาลัยคือ Big Data School โดยทาง IMC Institute จัดร่วมกับ ICE Solution และได้รับนักศึกษา 15 คนมาฝึกงานสองเดือนแบบ On the job training ในช่วงปิดเทอมในช่วงเดือน มิถุนายน จนถึง กรกฎาคม ปีที่ผ่านมา ซึ่งก็มีนักศึกษามาร่วมโครงการจากหลากหลายสถาบันทั้ง จุฬาลงกรณ์มหาวิทยาลัย ลาดกระบัง พระนครเหนือ มหาวิทยาลัยราชมงคลรัตนโกสินทร์ ธุรกิจบัณฑิต หรือมาไกลๆจาก มหาวิทยาลัยนครพนม มหาวิทยาลัยฟาฏอนี หรือนักศึกษาไทยในต่างประเทศอย่าง Wesleyan University
จริงๆโครงการนี้ได้แรงบันดาลใจมาจากรุ่นน้องคนหนึ่งที่เอารายการทีวีรื่อง “โรงเรียนฝึกคนหัวใจเพชร” ให้ดู ซึ่งเป็นโรงเรียนฝึกเด็กช่างไม้ในญี่ปุ่น สอนเด็กให้แกร่ง อดทน มีวินัยและใช้สมอง เห็นความยากลำบากในการเรียนกว่าจะออกมาเป็นช่างไม้ที่เก่งและมีคุณภาพ น้องเลยถามผมว่าเราทำโรงเรียนพัฒนาโปรแกรมเมอร์อย่างนี้ในเมืองไทยไหม ผมก็เลยเริ่มคิดถึงการฝึกคน ผมอาจจะยังไม่สามารถทำโรงเรียนฝึกโปรแกรมเมอร์หัวใจเพชรได้ทันที แต่ก็นึกขึ้นมาว่าวันนี้อุตสาหกรรมไอทีในบ้านเราหาโปรแกรมเมอร์เก่งๆได้ยากโดยเฉพาะคนที่ซื่อสัตย์และตั้งใจทำงานให้กับหน่วยงาน ไม่ใช่แค่คิดหวังจะร่ำรวย นอกเหนือจากมีความรู้ ก็ต้องอดทนและมีจริยธรรมที่ดี เรามาฝึกงานเขาไหม? อาจเป็นช่วงเวลาสั้นๆ 2-3 เดือน พอฝึกงานเสร็จมาเขาจะกลับไปเรียนต่อหรือไปทำงานที่ไหนก็ตามอย่างน้อยเราก็ได้สร้างประโยชน์ให้กับสังคมบ้าง พอคิดได้อย่างนี้ก็เริ่มคุยกับเพื่อนและอาจารย์บางคนแล้วบอกว่า กลางเดือนปีที่ผ่านมาผมก็เริ่มทำ Big Data Intern School ฝึกงานนักศึกษา 15 คนให้ทำ Big Data แล้วก็กำหนดเป้าหมายสิ่งที่จะฝึกเขาดังนี้
- ให้เรียนรู้หลักการของ Big Data และเทคโนโลยีต่างๆ
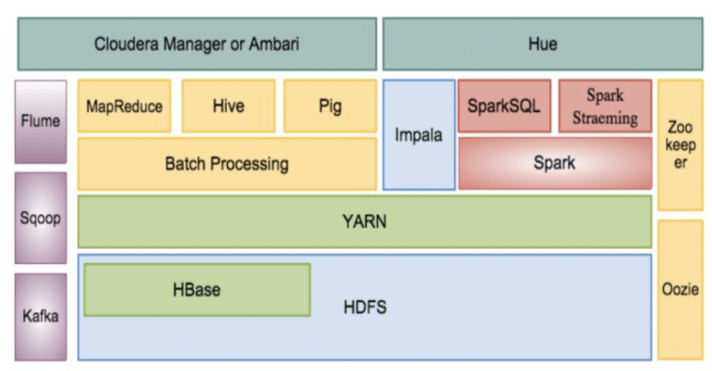
- สามารถติดตั้งระบบ Big Data ได้ไม่ว่าจะเป็น Apache Hadoop, Cloudera, Hortonworks, Amazon EMR และ Microsoft Azure HDInsight
- ให้ใช้ระบบ Cloud Computing อย่าง Amazon AWS และ Microsoft Azure ใที่ทางสถาบันจัดให้
- สามารถติดตั้งระบบ NoSQL ต่างๆอย่าง Cassandra, NoSQL, MongoDB
- เรียนรู้การประมวลข้อมูลขนาดใหญ่โดยใช้ Hive, Impala, Spark
- สามารถที่จะดึงข้อมูลเข้าโดยใช้เทคโนโลยีอย่าง Sqoop, Flume, Kafka
- เรียนรู้การทำ Machine Learning โดยใช้ภาษา R, Spark MLLib หรือเครื่องมืออย่าง Azure Machine Learning
- ทำโปรเจ็คด้าน Big Data กับบริษัท

ผมเองก็ได้อาจารย์ประจำสถาบันไอเอ็มซีหลายท่านเข้ามาช่วยอบรมนักศึกษาทั้ง 15 คน อาทิเช่น อ.โกเมษ จันทวิมล,อ.ธีรชัย หลาวทอง, อ.ชินวิทย์ ชลิดาพงศ์, อ. อารยา ฟลอเรนซ์และตัวผมเอง เข้ามาสอน รวมถึงคุณดนุพล สยามวาลา และก็มีรุ่นพี่จาก Ice Solution สองคนเข้าช่วยเป็นพี่เลี่ยงตลอดทั้งสองเดือน นักศึกษาเองก็ได้เรียนรู้จากที่ทางอาจารย์สอนและฝึกหัดทำเรื่องต่างๆด้วยตัวเอง โดยการฝึกงานในช่วงต้นจะฝึกเน้นให้นักศึกษามีความเข้าใจเรื่องของ Big Data Technology ต่างๆ และ Big Data Architecure จากนั้นก็จะเป็นการเน้นการใช้เทคโนโลยี Hadoop โดยให้นักศึกษาแบ่งกลุ่มกันติดตั้ง Hadoop Distribution ต่างๆทั้ง Cloudera, Hortoworks, MapR และ Pure Apache Hadoop แล้วทำการเปรียบเทียบกัน ซึ่งนักศึกษาก็สามารถทำได้เป็นอย่างดี โดยได้ลงมือติดตั้งบน Server cluster บน Cloud สุดท้ายก็ให้นักศึกษาได้เรียนรู้การทำ Big Data Analytics และ Machine Learning Techniques โดยใช้เครื่องมือต่างๆอย่าง Apache Spark, Spark MLlib และ Azure Machine Learning
ตลอดเวลาสองเดือนนักศึกษาได้ฝึกทักษะด้าน Big Data เป็นอย่างดี ซึ่งนักศึกษาที่มาฝึกงานมีทั้งปี 2 ปี 3 รวมถึงนักศึกษาปีที่ 4 จบแล้ว 3-4 คนซึ่งยอมมาฝึกงานก่อนออกไปทำงาน ผลของการฝึกงานก็ทำให้นักศึกษาเหล่านี้สามารถลงมือทำการวิเคราะห์ข้อมูลขนาดใหญ่โดยใช้ Hadoop และเทคโนโลยีต่างๆได้ และทุกคนก็ได้ใช้ผลของการฝึกงานเข้าไปทำงานในบริษัทต่างๆได้ นักศึกษาที่ฝึกงานในโครงการนี้ก็ยังสามารถแสดงความสามารถไปชนะการประกวดด้าน Big Data Analytics ต่างๆ ทั้งงาน Big Data Challenge ของ IMC Institute เองที่ต้องแข่งกับผู้ใหญ่และนักพัฒนาที่ทำงานแล้ว และก็ไปได้รางวัลการประกวด Data Science Contest ของสถาบันบัณฑิตพัฒนบริหารศาสตร์ (NIDA) ซึ่งผลของการฝึกงานทางสถาบันไอเอ็มซีก็ถือว่าเป็นความภาคภูมิใจอย่างหนึ่งที่เราได้ทำเพื่อพัฒนาบุคลากรเข้าสู่ภาคอุตสาหกรรม
สำหรับในปีนี้ทางสถาบันไอเอ็มซีตั้งใจจะรับนักศึกษามาฝึกงานในโครงการ Big Data School รุ่นที่สอง โดยในปีนี้เน้นจะรับนักศึกษาปีที่ 4 ที่จบการศึกษาแล้วแต่ต้องการฝึกงานเพื่อเรียนรู้เพิ่มเติมอีกสองเดือนก่อนเข้าไปทำงานในภาคอุตสาหกรรม โดยทางสถาบันเองจะร่วมมือกับบริษัท NetBay และบริษัทสยามวาลา เพื่อร่วมกันพัฒนา Big Data Platform และให้นักศึกษาได้ทดลองฝึกงานกับโจทย์จริงในภาคอุตสาหกรรม นอกจากนี้ยังมุ่งเน้นให้นักศึกษาได้เรียนเพื่อที่จะสอบประกาศนียบัตรระดับสากลอย่าง CCA Spark and Hadoop Developer Exam (CCA175) โดยทางสถาบันจะสนับสนุนค่าใช้จ่ายจำนวนหนึ่งให้กับนักศึกษาที่คาดว่าน่าจะสอบผ่าน
สำหรับกำหนดการ การฝึกงานในปีนี้จะมีโปรแกรมคร่าวๆดังนี้
29 พฤษภาคม วันแรกแรกการฝึกงาน จัดปฐมเทศ อบรมระเบียบวินัย ศึกษาแนวโน้มของเทคโนโลยี
30พฤษภาคม – 3 มิถุนายน เรียนรู้ระบบ Public Cloud ของค่ายต่างอาทิเช่น Google Cloud, Amazon Web Services, Microsoft Azure การใช้บริการต่างๆ อาทิเช่น Virtual Server, Cloud Storage, Auto-Scaling Servers, Application Development Servers รวมถึงศึกษาเรื่อง Docker
5 – 10 มิถุนายน เรียนรู้หลักการของ Big Data Architecture การติดตั้ง Apache Hadoop การติดตั้ง Hadoop Cluster และการติดตั้ง Cloudera/Hortonworks Cluster รียนรู้ NoSQL และติดตั้งระบบต่างๆทั้ง Cassandra, MongoDB และ HBase ร่วมถึงระบบอย่าง ElasticSearch และ Solr
12-17 มิถุนายน เรียนรู้บริการต่างๆของ Hadoop ต่อ การใช้บริการต่างๆทั้ง Hive, Impala, Flume, Sqoop, Kafka, Cloudera Manager, Amabari และให้เขียนข้อสรุปเปรียบเทียบ Big Data ต่างๆ
19-24 มิถุนายน เรียนรู้ Apache Spark และการทำ Big Data Analytics โดยใช้ Spark Python, Spark Scala, Spark SQL และ Spark Streaming
26 มิถุนายน – 1 กรกฎาคม เรียนรู้ Machine Learning การใช้เครื่องมือและภาษาต่างๆอาทิเช่น , MLLib และ Azure Machine Learning และติวการสอบ CCA Spark and Hadoop Developer Exam
3-27 กรกฎาคม ทำ Mini-Project
28 กรกฎาคม นำเสนอ Mini-Project และปิดการฝึกงาน
ทั้งนี้การอบรมเชิงฝึกงานครั้งนี้ไม่มีค่าใช้จ่ายใดๆ ซึ่งทางสถาบันคาดว่าผู้ที่ผ่านการอบรมจะเป็นผู้ที่เข้าใจหลักการและเทคโนโลยีด้าน Big Data พร้อมทั้งสามารถทำด้าน Data Science ได้ โดยทางสถาบันจะมีการสอบและวัดผลสัมฤทธิ์ของการฝึกงาน และทางสถาบันจะออกใบรับรองว่าผ่านการฝึกงาน และผู้ที่ผ่านหากต้องการไปฝึกงานหรือทำสหกิจศึกษา การทำโครงการเพิ่มเติมระหว่างเรียน ทางสถาบันจะติดต่อและให้การรับรองให้ พร้อมกันนี้นักศึกษาที่ทำคะแนนสอบจากการทดลองสอบ CCA Spark and Hadoop Developer Exam สูงสุดสามอันดับแรกทางสถาบันจะออกค่าใช้จ่ายการสอบจริงให้มูลค่ารายละ $295 เพื่อให้ได้ประกาศนียบัตร ทั้งนี้ผู้เข้าอบรมไม่มีอะไรต้องผูกมัดกับทางสถาบัน และทางสถาบันยินดีประสานติดต่อกับบริษัทอื่นๆเพื่อไปทำงานด้าน Big Data ต่อไป
สำหรับคุณสมบัติผู้ที่จะเข้ารับการอบรมนี้มีดังนี้
- กำลังศึกษาหรือสำเร็จการศึกษาในระดับปริญญาตรีสาขาวิศวกรรมคอมพิวเตอร์ วิทยากรคอมพิวเตอร์ หรือเทคโนโลยีสารสนเทศ [ถ้าเป็นนักศึกษาปี 4 ที่กำลังจบการศึกษาจะได้รับการพิจารณาก่อน]
- มีความตั้งใจจะเข้าฝึกงานจริงจัง อาจเป็นส่วนหนึ่งของการจบการศึกษาหรือไม่ก็ได้
- สามารถเข้าฝึกงานได้ตั้งแต่วันจันทร์-ศุกร์ เวลา เวลา 8.30 – 17.30 น.
- ต้องเข้ามาฝึกงานทุกวันตามข้อตกลงและต้องมีเวลาเข้าฝึกงานไม่น้อยกว่า 95%
ผู้ที่มีความสนใจการอบรมนี้สามารถดูรายละเอียดเพิ่มเติมได้ที่ http://www.imcinstitute.com/bigdataschool พร้อมทั้งส่งใบสมัครออนไลย์และติดต่อที่สถาบันไอเอ็มซี ก่อนวันที่ 31 มีนาคม 2560
ธนชาติ นุ่มนนท์
IMC Institute
กุมภาพันธ์ 2560