ในปี 2022 แนวโน้มของสถาบัตยกรรม Big Data กำลังเปลี่ยนไปจากเดิมที่กล่าวถึง Hadoop หรือ Data Lake ก็จะกลายเป็นเรื่องของ Big Data on Cloud และ Data Lakehouse มากขึ้น
ผมได้เคยเขียนบทความ Big Data Architecture มาหลายตอนเพื่อให้ได้อ่านกัน จะได้เข้าใจได้ว่า การออกแบบสถาปัตยกรรม Big Data ควรต้องใช้เทคโนโลยีอย่างไรบ้าง โดยผมมองระบบ Big Data เหมือนระบบไอทีทั้วไปที่จะต้องมี
- Input ซึ่งในที่นี้คือ Big Data ที่มีคุณลักษณะ 4V คือ Volume, Velocity, Variety และ Veracity
- Process/System ซึ่งในที่นี้คือ Big Data Pipeline หรือ Big Data Architecture
- Output ซึ่งในที่นี้ก็คือผลลัพธ์ที่ได้จากการวิเคราะห์ Big Data ซึ่งอาจเป็นแบบ Business Intelligence หรือ Data Science
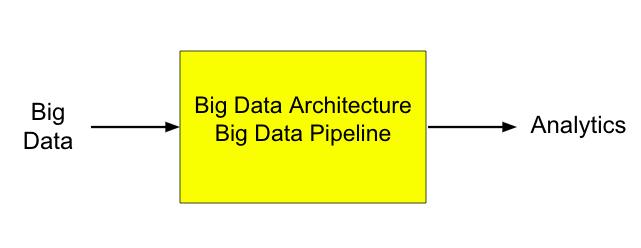
ทั้งนี้ Architecture อาจจะเปลี่ยนแปลงไปขึ้นอยู่กับคุณลักษณะของข้อมูลและผลลัพธ์ที่ต้องการ บทความที่ผมเขียนต้องการสรุปให้ทุกคนเข้าใจและตอบคำถามต่างๆได้อาทิเช่น
- อะไรคือความแตกต่างระหว่าง Data Warehouse และ Data Lake
- การออกแบบ Big Data Architecture จำเป็นต้องการ Hadoop หรือไม่
- การออกแบบสถาปัตยกรรมโดยใช้ Public Cloud Services ต้องใช้บริการอะไรบ้าง
- สถาปัตยกรรมในการวิเคราะห์ข้อมูลแบบ Streaming เป็นอย่างไร
- สถาปัตยกรรม Data Lakeshore ที่กำลังพูดถึงในปัจจุบันว่าจะมาแทนที่ Data Lake คือออะไร
- ความหมายของ Data Fabric
ซึ่งบทความของผมมีทั้งหมด 11 ตอนโดยมีหัวข้อต่างๆดังนี้
- ตอนที่ 1 : Big Data Pipeline ทำไมไม่ใช่ Data Warehouse
- ตอนที่ 2 : สถาปัตยกรรมบน Data Lake
- ตอนที่ 3 : จาก Hadoop แบบ On-Premise สู่การใช้บริการบน Public cloud
- ตอนที่ 4 : สถาปัตยกรรม Data platform บน Public cloud
- ตอนที่ 5 : สถาปัตยกรรม Data platform สำหรับประมวลผลข้อมูลแบบ Streaming
- ตอนที่ 6 : สถาปัตยกรรม Cloud Data platform สำหรับประมวลผลข้อมูลทั้งแบบ Batch และ Streaming
- ตอนที่ 7: แนวโน้มสถาปัตยกรรม Big Data 2022
- ตอนที่ 8: การจัดการข้อมูลบน Data Lake
- ตอนที่ 9: สถาปัตยกรรม Data Lake + Data Warehouse
- ตอนที่ 10: สถาปัตยกรรม Data Lakehouse
- ตอนที่ 11: สถาปัตยกรรม Data Fabric
ส่วนผู้ที่สนใจอยากศึกษาเพิ่มเติมทาง IMC Institute ก็มีบันทึกวิดีโอรายการย้อนหลังรายตอนที่เกี่ยวข้องกับ Big Data architecture โดยเผยแพร่ไว้ที่ YouTube channel ของ IMC Institiute และก็มีหลักสูตรด้าน Big Data Architecture Design ที่จะทำการสอนทุกสามเดือน
ธนชาติ นุ่มนนท์
IMC Institute
