วันนี้มางาน Strata + Hadoop World ที่สิงคโปร์วันแรกซึ่งเป็นวัน Tutorial ผมเลือกที่จะเข้าสอง session คือ Hadoop Application Architectures ในตอนเช้าและ Apache Hadoop Operations for production systems ในตอนบ่าย
Session แรกน่าสนใจมากเพราะผู้บรรยายทั้งสี่ท่านคือคนเขียนหนังสือเรื่อง Hadoop Application Architectures และได้แนะนำสถาปัตยกรรมของ Hadoop สำหรับการวิเคราะห์ข้อมูล Network Fraud แบบ Near Real Time ดังรูปที่ 1

รูปที่ 1: Architecture สำหรับ Fraud Detection
จาก Architecture นี้มีประเด็นที่น่าสนใจคือ
Storage: เลือกใช้ HDFS สำหรับเก็บข้อมูลที่ดึงมาจาก Network และต้องการประมวลผลแบบ Batch และเลือก HBase สำหรับการเก็บ Profiile ของ Network ที่ต้องการอ่านและเขียนอย่างรวดเร็ว นอกจากนี้ยังมีการพูดถึง Kudu ว่าน่าจะเป็นเทคโนโลยีใหม่ที่อาจเหมาะกับการเก็บข้อมูลที่ Google ค้นคิดขึ้นมาที่ผสมระหว่าง HDFS และ HBase ดังรูปที่ 2
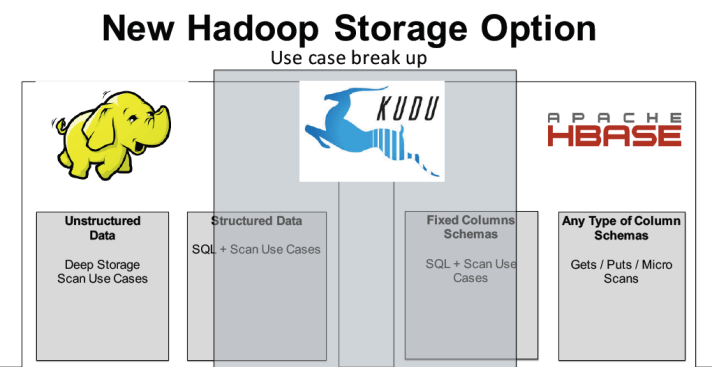
รูปที่ 2 Kudu
Ingestion: มี Workflow ในการดึงข้อมูลจาก Network Devices ดังรูป โดยขั้นตอนแรกดึงข้อมูลมาเก็บใน Queue โดยใช้ Kafka และใช้ Flume ทำหน้าที่เป็น Event Handler จัดการเลือกเฉพาะข้อมูลที่น่าสงสัย
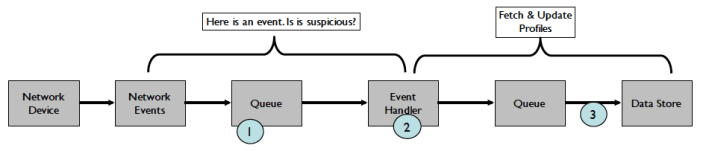
รูปที่ 3 Ingestion Workflow
Processing: ในการประมวลผลข้อมูลมีได้หลายวิธีดังรูปที่ 4 แต่ในในกรณีของ Streaming เลือกใช้ Spark Streaming ส่วนกรณีของ Batch Processing เลือกใช้ Spark สำหรับการทำ Machine Learning, Impala สำหรับการทำรายงาน และ MapReduce ดังรูปที่ 5 โดยทีมงานก็พยายามเน้นให้เห็นว่า MapReduce กำลังถูกแทนที่ด้วย Spark และ Hive กำลังถูกแทนที่ด้วย Impala
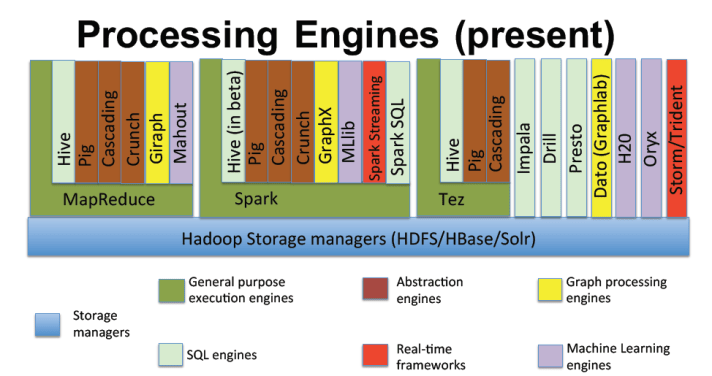
รูปที่ 4 การประมวลผลข้อมูลใน Hadoop ด้วยวิธีต่างๆ

รูปที่ 5 Processing สำหรับกรณีศึกษานี้
สรุปสิ่งที่ได้จาก Session นี้คือเห็นการเก็บข้อมูลที่ต้องผสมผสานทั้ง HDFS และ HBase การดึงข้อมูลคงต้องพิจารณาเรื่องของ KafKa และการประมวลผลควรเน้นเรื่องของ Spark และ Impala
ธนชาติ นุ่มนนท์
IMC Institute
ธันวาคม 2558
