ในตอนที่แล้วผมได้เขียนบทความให้เห็นว่าหากเราต้องการทำการประมวลผลข้อมูลแบบ Streaming เราอาจต้องปรับสถาปัตยกรรม Big data ให้เป็นแบบ Lambda หรือ Kappa และถ้าจะทำบนระบบ On-premise เราอาจต้องใช้เทคโนโลยีอย่าง Apache Kafka ที่มีทั้งการทำ Ingestion, Fast storage และ Real-time processing

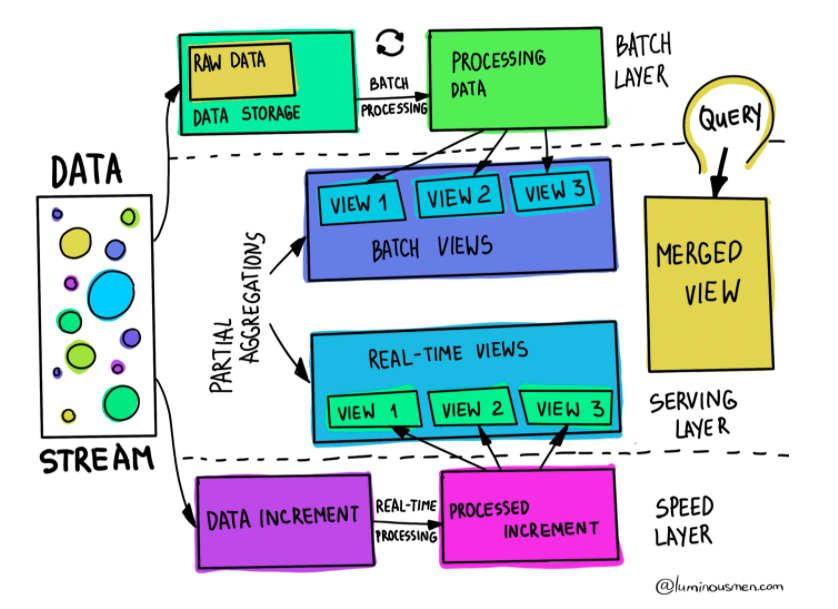
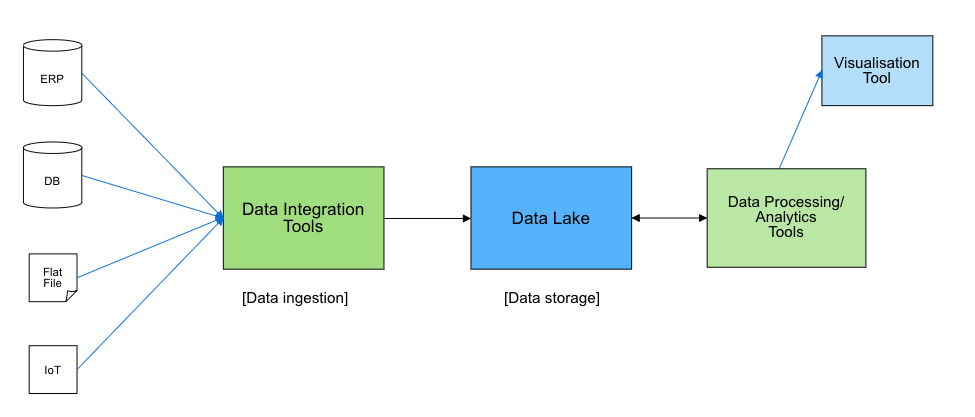
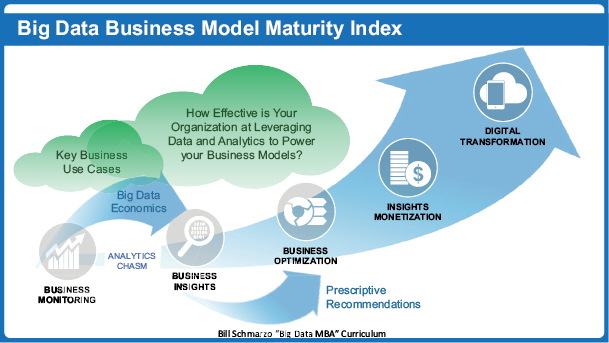
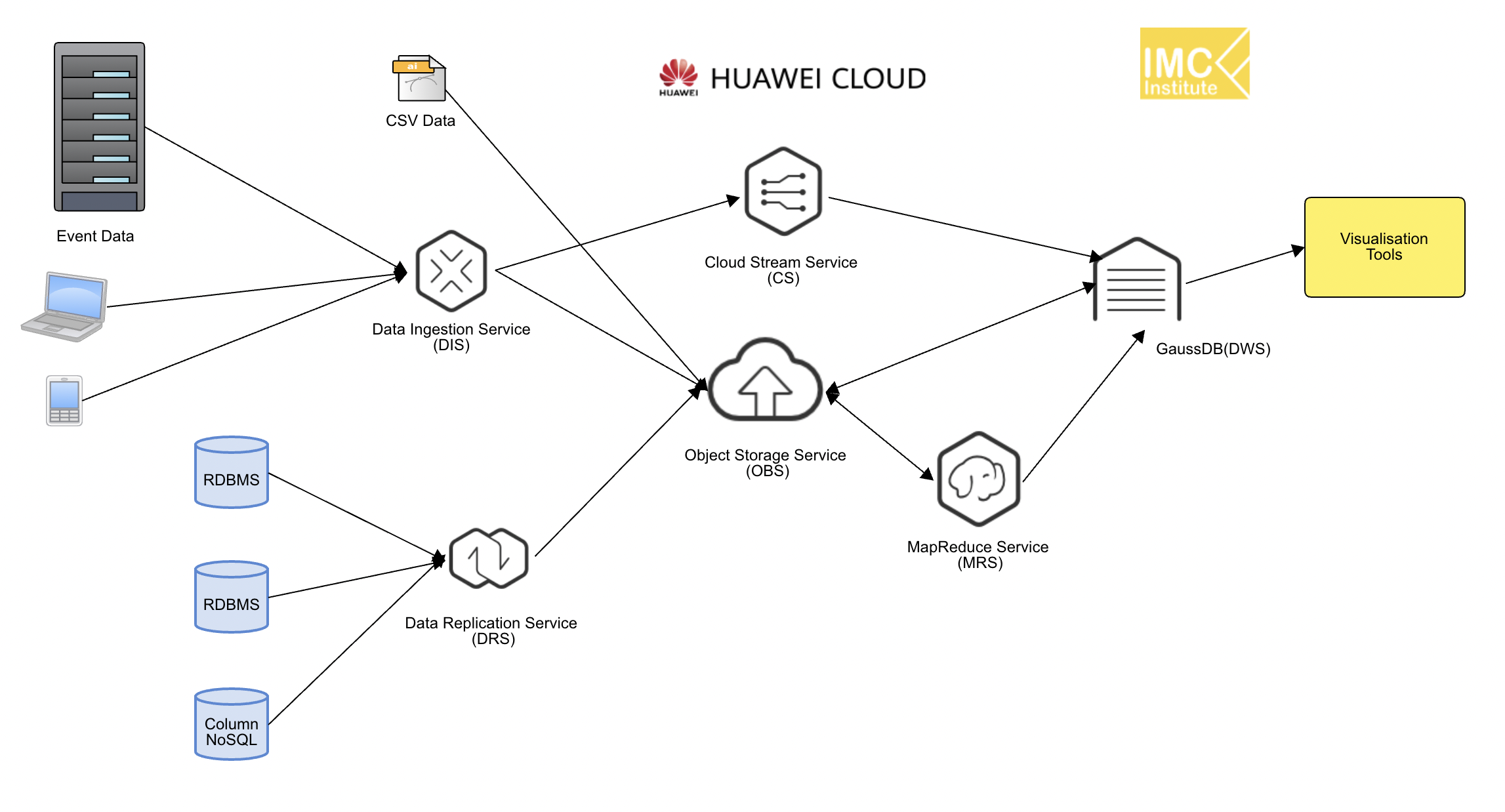
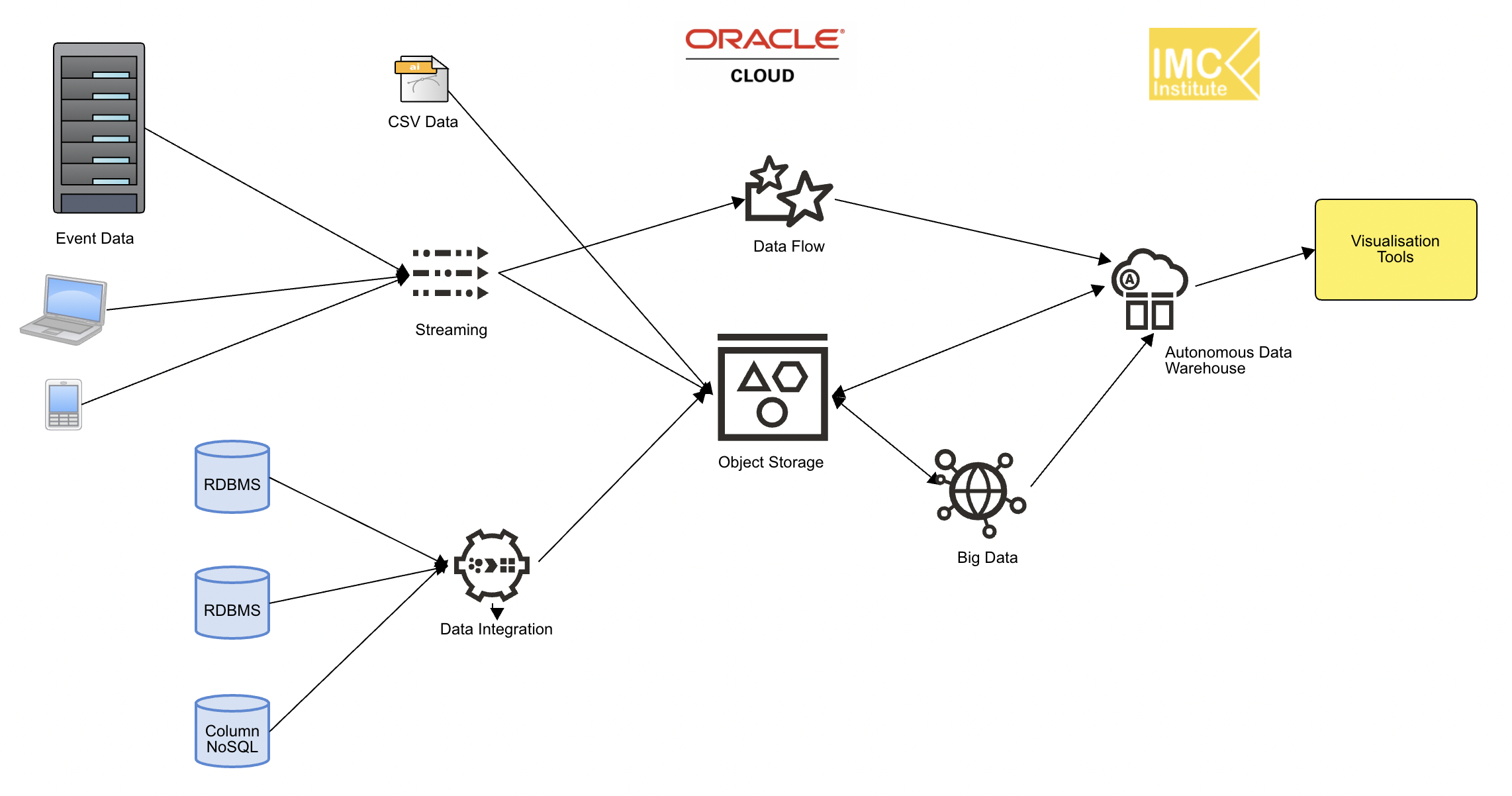
และเมื่อพิจารณาถึงการทำสถาปัตยกรรมบน Cloud เราอาจจะเห็นได้ว่าขั้นตอน Big Data Pipeline ที่เคยระบุว่ามี 5 อย่างคือ Ingestion, Storage, Processing, Analytics และ Visualisation เมื่อต้องการออกแบบให้ประมวลผลทั้งแบบ Bacth และ Streaming จะมีความซับซ้อนขึ้น โดยอาจต้องมี Storage, Processing และ Analytics ที่ใช้กับข้อมูลทั้งสองแบบคือ Batch และ Streaming รวมถึงอาจต้องมี Pipeline ที่ใช้ในการเก็บข้อมูลสำหรับ Serving layer โดยจะมีสถาปัตยกรรมดังรูปที่ 1 ที่มีองค์ประกอบต่างๆดังนี้
- Ingestion ที่จะนำข้อมูลเข้ามาทั้งแบบ Batch และ Streaming
- Storage ในการเก็บข้อมูลที่อาจแบ่งเป็น Fast storage สำหรับข้อมูลแบบ Streaming และ Data Lake สำหรับข้อมูลแบบ Batch
- Processing/Analytics ในการประมวลและวิเคราะห์ข้อมูลที่อาจแบ่งเป็น Batch Processing/Analytics และ Real-time Processing/Analytics
- Serving layer ที่อาจเป็น Data Warehouse หรือ No SQL ที่จะทำหน้าที่เก็บผลลัพธ์ของการประมวลผลข้อมูลทั้งสองแบบ
- Visualisation ส่วนที่เป็นการแสดงผลที่อาจจะดึงมาจาก Serving layer
จากสถาปัตยกรรมข้างต้นนี้ หากไปเปรียบเทียบกับสถาปัตยกรรม Data Platform เดิมที่อยู่บน Cloud ซึ่งผมเคยได้สรุปไว้ในบทความ Big Data Architecture #4: สถาปัตยกรรม Data platform บน Public cloud จะพบว่ามีบริการที่อาจต้องนำเพิ่มขึ้นมาดังนี้
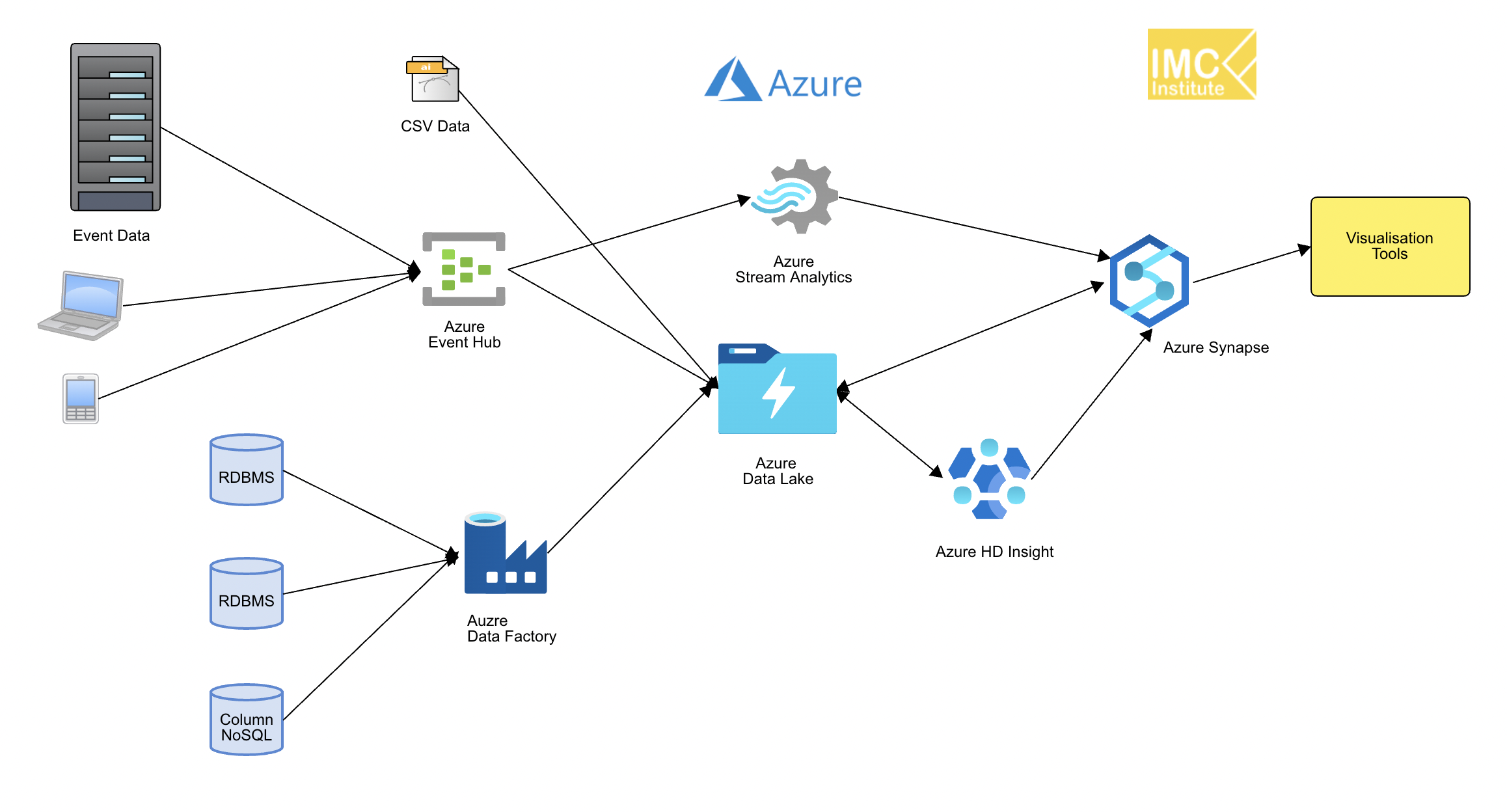
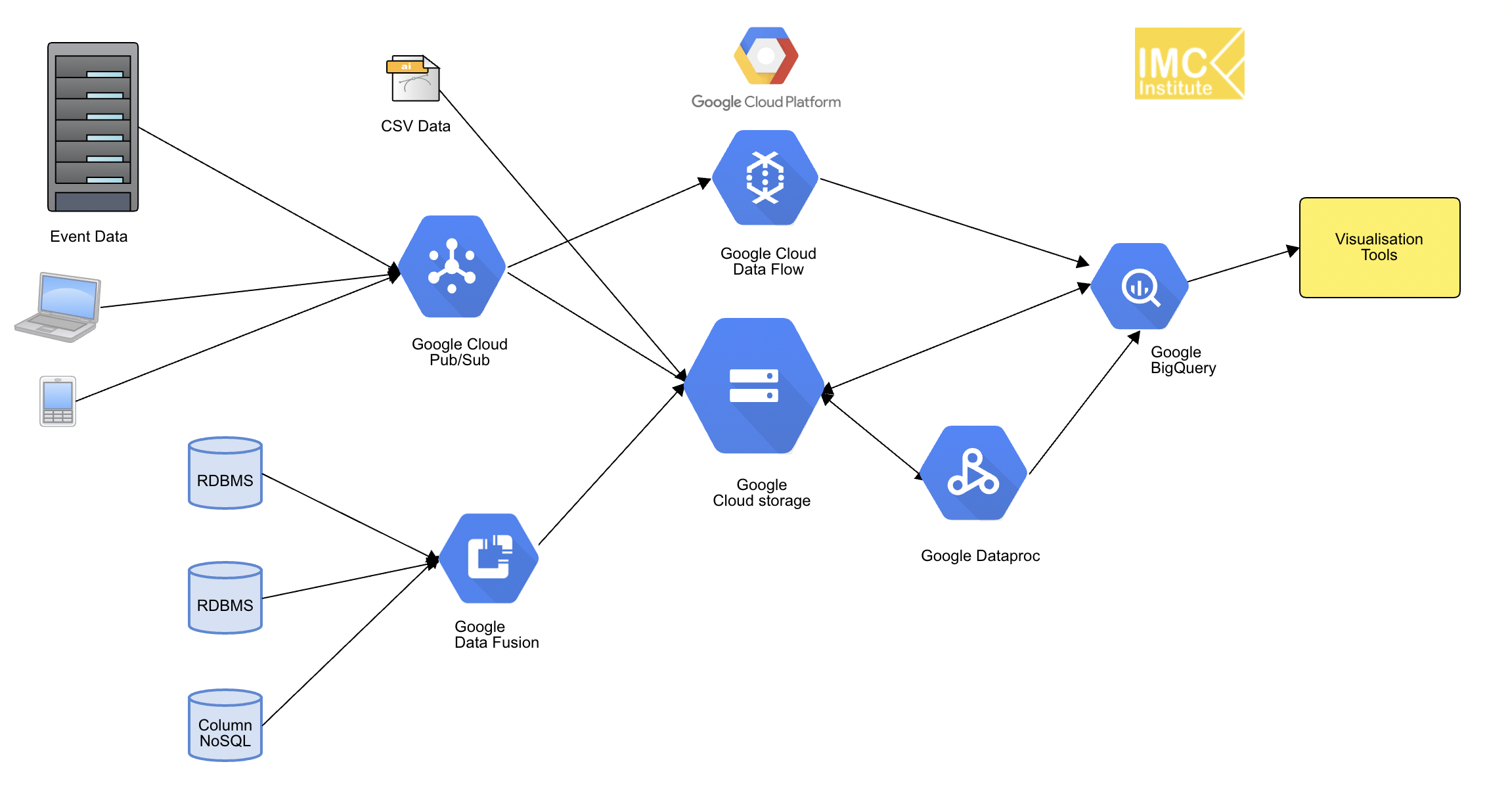
- Fast storage อย่าง อย่าง Azure Event Hub, Google Cloud Pub/Sub หรือ AWS Kinesis เพื่อทำหน้าที่เป็น Storage หลักในการเก็บข้อมูล Streaming
- Real-time processing อย่าง Azure Stream Analytics, Google Cloud DataFlow หรือ AWS Kinesis Stream Analytics
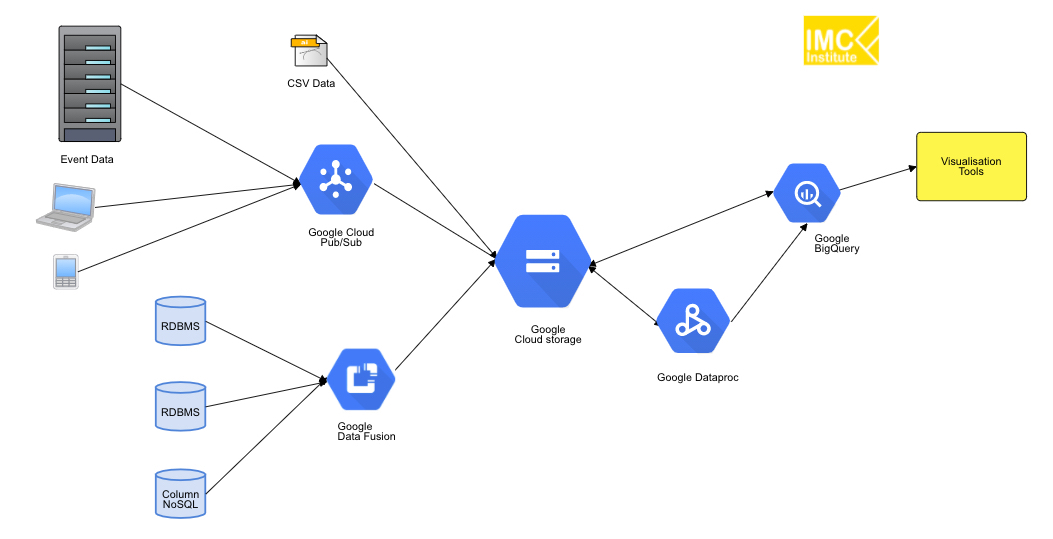
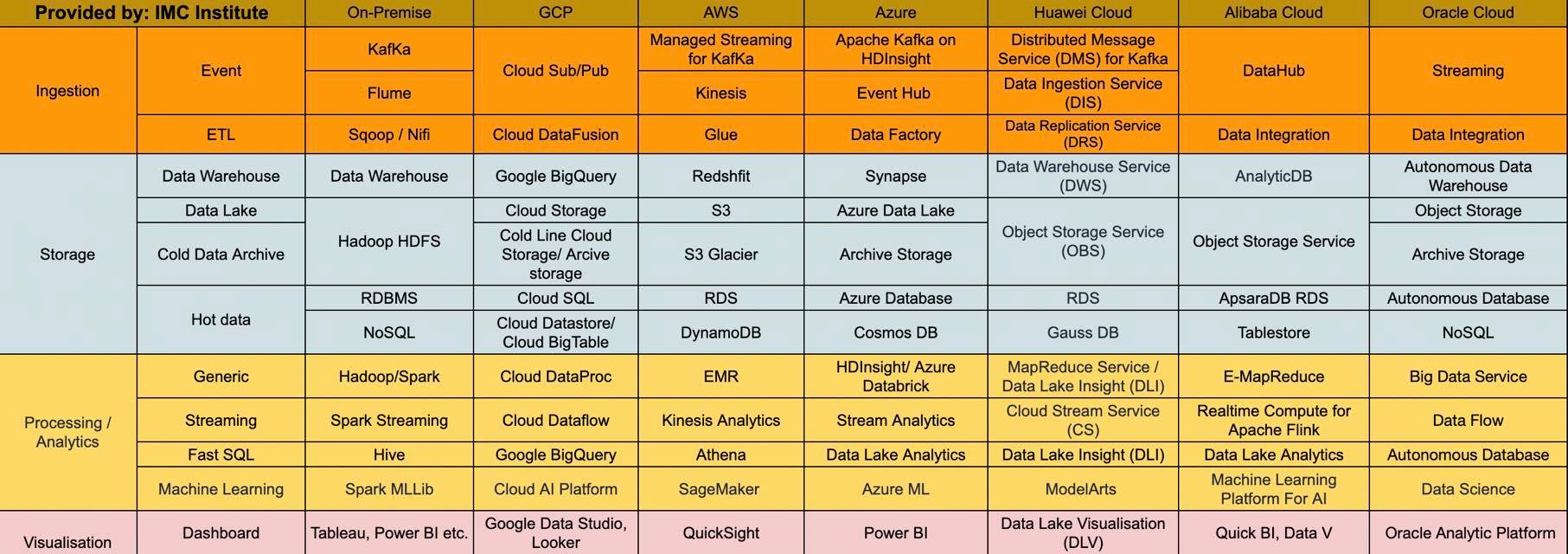
โดย Cloud Data Platform สำหรับผู้ให้บริการ Cloud สามรายหลักคือ Microsoft Azure, Google Cloud Platform และ AWS, Huawei Cloud, Alibaba Cloud และ Oracle cloud จะได้ Block diagram ดังรูปที่ 2 – 7


ธนชาติ นุ่มนนท์
IMC Institute