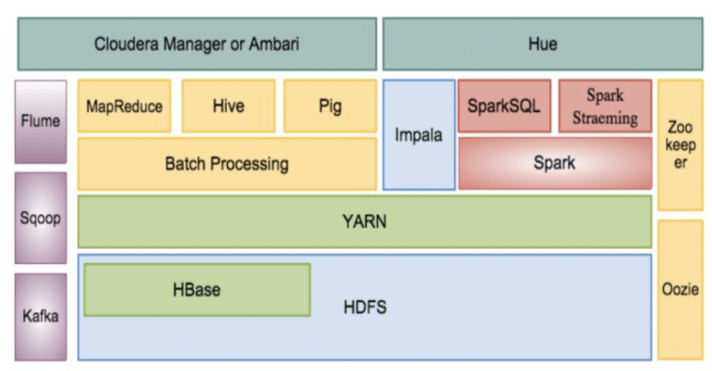
ช่วงหลายเดือนที่ผ่านมาผมเดินสายบรรยายเรื่อง Big Data Jumpstart โดยแนะนำให้องค์กรต่างๆทำ Big Data as a Service ซึ่งเป็นการใช้ Cloud Services ของ Public cloud หลายใหญ่ต่างๆทั้ง Google Cloud Platform, Microsoft Platform หรือ Amazon Web Services (AWS) ทำให้เราสามารถที่จะลดค่าใช้จ่ายได้มหาศาลโดยเฉพาะกับองค์กรขนาดกลางหรือขนาดเล็กที่ไม่มีงบประมาณหลายสิบล้านในการลงทุนโครงสร้างพื้นฐานด้าน Big Data

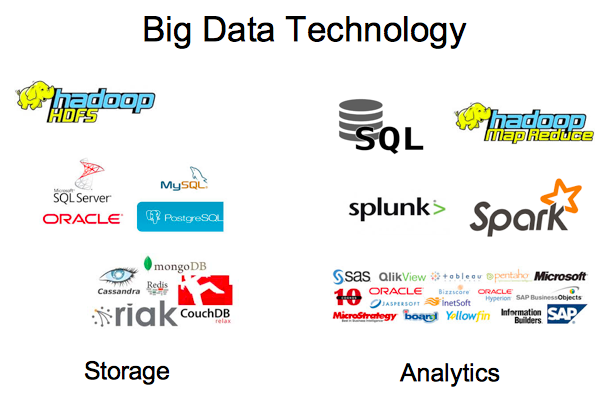
รูปที่ 1 องค์ประกอบของเทคโนโลยีสำหรับการทำ Big Data
การลงทุนโครงสร้างพื้นฐานหรือการจัดหาเทคโนโลยีสำหรับโครงการ Big Data โดยมากจะมีการลงทุนอยู่สี่ด้านคือ 1) Data Collection/Ingestion สำหรับการนำข้อมูลเข้ามาเก็บ 2) Data Storage สำหรับการเก็บข้อมูลที่เป็นทั้ง structure และ unstructure 3) Data Analysis/Processing สำหรับการประมวลผลข้อมูลที่อยู่ใน data storage และ 4) Data visualisation สำหรับการแสดงผล
ปัญหาที่องค์กรต่างๆมักจะมีก็คือการจัดหาเทคโนโลยีด้าน Data storage ที่จะต้องสามารถเก็บ Big Data ซึ่งนอกจากจะมีขนาดใหญ่แลัวข้อมูลยังมีความหลากหลาย จึงต้องหาเทคโนโลยีราคาถูกอย่าง Apache Hadoop มาเก็บข้อมูล แต่การติดตั้งเทคโนโลยีเหล่านี้ก็มีค่าใช้จ่ายในการหาเครื่องคอมพิวเตอร์ Server จำนวนมากมาใช้ และค่าใช้จ่ายด้าน Hardware ก็ค่อนข้างสูงหลายล้านบาท บางทีเป็นสิบล้านหรือร้อยล้านบาท ซึ่งอาจไม่เหมาะกับองค์กรขนาดเล็ก หรือแม้แต่องค์กรขนาดใหญ่ก็มีคำถามที่จะต้องหา Use case ที่ดีเพื่อตอบเรื่องความคุ้มค่ากับการลงทุน (Returm of Investment) ให้ได้
ดังนั้นการทำโครงการ Big Data ไม่ควรจะเริ่มต้นจากการลงทุนเรื่องเทคโนโลยี ไม่ใช่เป็นการจัดหาระบบอย่างการทำ Apache Hadoop แต่ควรจะเป็นการเริ่มจากคิดเรื่องของธุรกิจเราต้องคิดเรื่องของ Business Transformation (Don’t thing technology, think business transformation) การทำโครงการ Big Data ควรเริ่มจากทีมด้านธุรกิจไม่ใช้หานักเทคโนโลยีมาแนะนำการติดตั้งระบบหรือลง Hadoop หรือหานักวิทยาศาสตร์ข้อมูลมาทำงานทันที เพราะหากฝ่ายบริหารหรือฝ่ายธุรกิจมีกลยุทธ์ด้าน Big Data เข้าใจประโยชน์ของการทำ Big Data ได้ เราสามารถเริ่มต้นโครงการ Big Data ได้อย่างง่าย โดยใช้ประโยชน์จากบริการ Big Data as a Service บน Public cloud ซึ่งทำให้องค์กรไม่ต้องเสียค่าใช้จ่ายเริ่มต้นในราคาแพง ที่อาจไม่คุ้มค่ากับการลงทุน
เทคโนโลยีในการทำ Big Data ต่างๆเช่น Big data storage (อย่าง Hadoop HDFS) เราสามารถใช้ Cloud Storage อย่าง Amazon S3, Google Cloud Storage หรือ Azure Blob เข้ามาแทนที่ได้ โดยบริการเหล่านี้ค่าใช้จ่ายในการใช้จ่ายในการใช้งานจะต่ำกว่าการติดตั้ง Hadoop มาใช้งานเป็นสิบหรือร้อยเท่า แม้อาจมีข้อเสียเรื่องเวลาในการ Transfer ข้อมูลจาก site ของเราขึ้น Public Cloud แต่หากมีการวางแผนที่ดีแล้วสามารถทำงานได้อย่างมีประสิทธิภาพ เช่นเดียวกับเรื่องความปลอดภัยของข้อมูบบน Public cloud หากมีการพิจารณาการใช้ข้อมูลที่เหมาะสมหรือการเข้ารหัสข้อมูลก็จะตัดปัญหาเรื่องเหล่านี้ไปได้
เช่นเดียวกันในการประมวลผลเราสามารถใช้บริการบน Public cloud ที่ใช้ระบบประมวลผลอย่าง Hadoop as a service เช่น DataProc บน Google Cloud Platform, HDInsight ของ Microsoft Azure หรือ EMR ของ AWS ซึ่งมีค่าใช้จ่ายตามระยะเวลาการใช้งาน (pay-as-you-go) ซึ่งเราไม่จำเป็นต้องเปิดระบบตลอด และมีค่าใช้จ่ายที่ต่ำมาก รวมถึงการใช้บริการอื่นๆอย่าง Machine Learning as a Service บน public cloud ที่มีความสามารถที่ค่อนข้างสูง ทำให้เราสามารถทำงานได้อย่างมีประสิทธิภาพ
แม้แต่การทำ Data Visualisation เราก็สามารถที่จะใช้เครื่องมือบน public cloud ที่จัดเป็น Big Data Software as a Service อย่างเช่น Google Data Studio 360, PowerBI บน Microsoft Azure หรือ Quicksight ของ AWS ได้ ซึ่งรูปที่ 2 ก็แสดงสรุปให้เห็นบริการ Cloud Service เหล่านี้ บน public cloud platform ต่างๆ
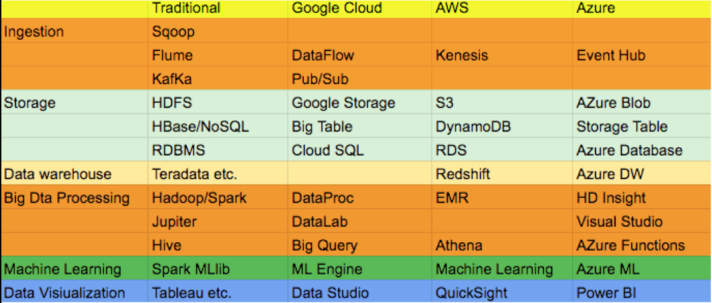
รูปที่ 2 Tradition Big Data Technology เทียบกับ Big Data as a Service ต่าง
ซึ่งการทำโครงการ Big Data โดยใช้ public cloud เหล่านี้สามารถที่จะเริ่มทำได้เลย ไม่ได้มีค่าใช้จ่ายเริ่มต้น และค่าใช้จ่ายที่ตามมาก็เป็นค่าบริการต่อการใช้งาน ซึ่งค่าบริการที่อาหมดไปหลักๆก็จะเป็นค่า Cloud Storage ที่อาจเสียประมาณเดือนละไม่ถึงพันบามต่อ Terabyte และหากเราต้องการเปลี่ยนแปลงหรือยกเลิกบริการเหล่านี้ก็สามารถใช้ได้ทันที ซึ่งวิธีการตัดสินใจที่จะทำโครงการ Big Data เหล่านี้ก็จะไม่ได้เน้นเรื่องของความคุ้มค่ากับการลงทุนมากนัก เพราะค่าใช้จ่ายเริ่มต้นต่ำมาก แต่มันจะกลายเป็นว่า เราจะทำโครงการอะไรที่ให้ประโยชน์กับธุรกิจมากสุด และเมื่อเริ่มทำลงทุนเรื่มต้นเล็กน้อยก็จะเห็นผลทันทีว่าคุ้มค่าหรือไม่
กล่าวโดยสรุป วันนี้เราสามารถเริ่มทำโครงการ Big Data ได้เลยโดยเริ่มที่โจทย์ทางธุรกิจ คุยกับฝั่งธุรกิจ ไม่ใช่เริ่มที่เทคโนโลยี
ธนชาติ นุ่มนนท์
IMC Institute
ตุลาคม 2560