เมื่อพูดถึง Big Data นอกเหนือจากข้อมูลจะมีขนาดใหญ่ขึ้นแล้ว รูปแบบของข้อมูลในอนาคตส่วนใหญ่ก็จะเป็น Unstructure และข้อมูลก็จะเพิ่มขึ้นอย่างรวดเร็ว ตามที่เรานิยามคุณลักษณะของ Big Data ด้วย 3V: Volume, Variety และ Velocity ดังนั้นเครื่องมือในการที่จะทำ Big Data ก็จะต้องเปลี่ยนไปจากที่เราเคยใช้ RDBMS ที่เป็น SQL คนก็เริ่มต้องหาเครื่องมืออื่นๆที่จะจัดการกับข้อมูลจำนวนมากได้อย่าง NewSQL เช่น MySQL Cluster, Amazon RDS หรือ Azure SQL หรือเครื่องมือที่เป็น NoSQL อย่าง MongoDB หรือ Cassandra และเครื่องมืออย่าง Hadoop ที่ใช้สำหรับจัดการ Unstructure Data ที่เป็น PetaByte
Hadoop เป็นหนึ่งในเครื่องมือ Big Data ที่ได้รับความสนใจอย่างกว้างเพราะสามารถที่จะจัดการข้อมูล Unstructure ขนาดใหญ่ได้ เช่นข้อมูลที่เป็น Text File, XML หรือ JSON ผมเองเจอไฟล์ที่เป็น Web Crawl อยู่ในรูปแบบของไฟล์ Web ARChive (WARC) ซึ่งเป็น Text ขนาดใหญ่ขนาดหลายร้อย TeraByte ซึ่งแน่นอนการจัดการข้อมูลแบบนี้ต้องหาเครื่องมือที่เหมาะสม และ Hadoop ก็คือเครื่องมือที่ผมเลือกใช้
Hadoop Project
Hadoop เป็น Open source Project ของ Apache สำหรับการเก็บและบริหารข้อมูลขนาดใหญ่ Hadoop เขียนด้วยโปรแกรมภาษาจาวา มีความสามารถในการทำ Fault Tourarent เพราะจะเก็บข้อมูลซ้ำกันในหลายๆที่ และเป็นระบบที่เป็น Horizontal Scale ที่รันบนเครื่อง commodity server จำนวนมาก Hadoop Project เริ่มต้นโดย Doug Cutting และ Mike Cafarella ที่เป็นทีมงานของบริษัท Yahoo ซึ่งต่อมาก็มีบริษัทอื่นๆนำไปใช้กันอย่างมากทั้ง eBay, Facebook และ Amazon รวมถึงมีบริษัทหลายๆรายที่นำมา Hadoop มาทำ Commercial Distribution อาทิเช่น Cloudera, MapR, IBM Infoshphere BigInsight, Hortonwork หรือ Amazon Elastic Map Reduce
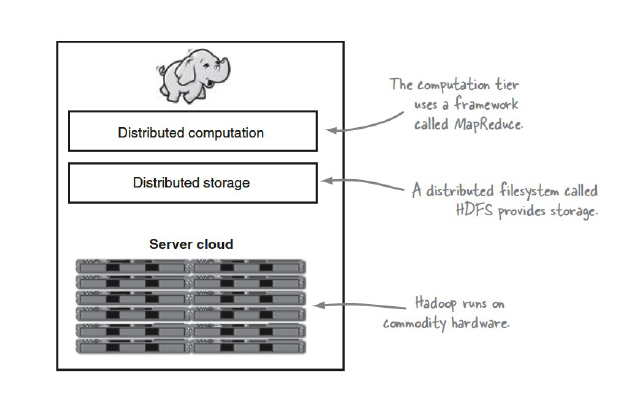
รูปที่ 1: Hadoop Environment [Source: Hadoop in Practice; Alex Holmes]
Hadoop เวอร์ชั่นแรกจะมีองค์ประกอบหลักสองส่วนคือ
- HDFS (Hadoop Distribution File System) ที่ทำหน้าที่เป็นส่วนเก็บข้อมูลซึ่งจะเก็บข้อมูลขนาดใหญ่ที่จะแบ่งเป็นไฟล์ย่อยขนาดใหญ่เก็บลงใน Data Node จำนวนมาก โดยจะมี Master Node ที่ทำหน้าที่ระบุตำแหน่งของข้อมูลที่เก็บใน Data node
- Map/Reduce จะเป็นส่วนประมวลผลข้อมูล ที่นักพัฒนาสามารถเขียนโปรแกรมโดยใช้ภาษาจาวามาวิเคราะห์ข้อมูลในรูปแบบของฟังก์ชันการ Map และ Reduce ได้ โดยระบบก็จะกระจาย Task ไปรันแบบ Parallel บนเครื่องหลายๆเครื่อง
ข้อมูลที่เก็บอยู่ใน HDFS จะไม่ใช่รูปแบบ Table อย่างที่เก็บในฐานข้อมูล RDBMS จะเหมาะกับการเก็บข้อมูลขนาดใหญ่มากที่ไม่ต้องมีการเปลี่ยนแปลง และไม่สามารถอ่านหรือเขียนข้อมูลแบบ Random Access ได้ ส่วนการประมวลผลแบบ Map/Reduce ก็ไม่ใช่ realtime Online แบบ SQL ของ RDBMS แต่จะเป็นแบบ Batch Offilne ใช้เวลาพอสมควรขึ้นอยู่กับขนาดข้อมูล
สถาปัตยกรรมฮาร์ดแวร์ของระบบ Hadoop จะประกอบด้วยเครื่อง Server จำนวนมาก โดยจะมีเครื่องหนึ่งทำหน้าที่เป็น Master และจะมีเครื่องลูกอีกจำนวนมากทำหน้าที่เป็น Slave โดยปกติ Hadoop จะกำหนดให้ข้อมูลที่เก็บในเครื่อง Slave มีการเก็บข้อมูลซ้ำกันสามแห่ง ดังนั้นเครื่อง Slave ควรจะมีอย่างน้อยสามเครื่อง ส่วนเครื่อง Master ก็จะทำหน้าที่หลักในการระบุตำแหน่งของข้อมูลและ Task ที่กระจายในการประมวลผลของ Map/Reduce ดังนั้นเครื่อง Master จึงมีความสำคัญอย่างมาก และต้องมีเครื่อง Secondary Master ในการที่จะสำรองไว้ในกรณีเครื่อง Master ตายไป ดังนั้นระบบ Hadoop โดยทั่วไปจะเริ่มต้นที่เครื่อง Server 5 เครื่อง สำหรับ Master หนึ่งเครื่อง, Secondary Master หนึ่งเครื่อง และ Slave สามเครื่อง โดยหากต้องการเก็บข้อมูลมากขึ้นหรือต้องการประมวลผลข้อมูลให้เร็วขึ้นก็ต้องเพิ่มจำนวนเครื่อง Slave ให้มากขึ้น ทั้งนี้ขนาดของข้อมูลที่เก็บได้ก็จะขึ้นอยู่กับขนาดความจุข้อมูลของเครื่อง Slave รวมกันหารด้วยจำนวนข้อมูลที่ต้องการเก็บซ้ำ (default คือ 3) ซึ่งการเก็บข้อมูลจำนวนเป็น Petabyte ได้ก็ต้องมีเครื่องเป็นจำนวนมากกว่าร้อยเครื่อง โดยปัจจุบัน Yahoo เป็น site ที่มี Hadoop Cluster ใหญ่ที่สุด โดยมีเครื่องจำนวนถึง 40,000 เครื่อง

รูปที่ 2: Hadoop Architecture [Source: Hadoop in Practice; Alex Holmes]
Hadoop Ecosystem
ระบบ Hadoop เองจะมีองค์ประกอบหลักอยู่แค่สองส่วนคือ HDFS และ Map/Reduce ซึ่งค่อนข้างจะไม่สะดวกกับผู้ใช้งานที่มีความต้องการอื่นๆเช่น การประมวลผลโดยใช้ภาษา SQL การเขียนหรืออ่านข้อมูลแบบ Random access หรือการถ่ายโอนข้อมูลจากที่อื่นๆ จึงมีการพัฒนาโปรเจ็คอื่นๆที่มาทำงานร่วมกับ Hadoop เพื่อให้ได้ประสิทธิภาพดียิ่งขึ้น ดังแสดงตัวอย่างในรูปที่ 3 ซึ่งมีเครื่องมือที่สำคัญดังนี้

รูปที่ 3: Hadoop Ecosystem [Source: Big Data Analytics with Hadoop: Phillippe Julio]
- Hive เป็นเครื่องมือสำหรับผู้ต้องการสืบค้น (Query) ข้อมูลที่เก็บใน HDFS ด้วยภาษาลักษณะ SQL แทนที่จะต้องมาเขียนโปรแกรม Map/Reduce โดย Hive จะทำหน้าที่ในการแปล SQL like ให้มาเป็น Map/Reduce แล้วก็ทำการรันแบบ Batch
- Pig เป็นเครื่องมือคล้ายๆกับ Hive ที่ช่วยให้ประมวลผลข้อมูลโดยไม่ต้องเขียนโปรแกรม Map/Reduce ซึ่ง Pig จะใช้โปรแกรมภาษา script ง่ายๆที่เรียกว่า Pig Latin แทน โดย Pigเหมาะกับการทำ ETL สำหรับการแปลงข้อมูลในรูปแบบต่างๆเช่น JSON
- Sqoop เป็นเครื่องมือในการถ่ายโอนข้อมูลระหว่างฐานข้อมูลที่อยู่รูปแบบ Table บน RDBMS อย่าง SQL server, Oracle หรือ MySQL กับข้อมูลบน HDFS ของ Hadoop
- Flume เป็นเครื่องมือในการดึงข้อมูลจากระบบอื่นๆแบบ Realtime เข้าสู่ HDFS เช่นการดึง Log จาก Web Server การดึงข้อมูลเหล่านี้จะต้องมีการติดตั้ง Agent ที่เครื่อง Server
- HBase เป็นเครื่องมือที่จะทำให้ Hadoop สามารถอ่านและเขียนข้อมูลแบบ Realtime Random Access ได้โดยจะทำให้เป็น BigTable ที่เก็บข้อมูลได้ไม่จำกัด row หรือ column ซึ่ง HBase ก็จะเป็นเสมือนการทำให้ Hadoop เป็น NoSQL Database
- Oozie เป็นเครื่องมือในการทำ Workflow จะช่วยให้เราเอาคำสั่งประมวลผลต่างๆของระบบ Hadoop เช่น Map/Reduce, Hive หรือ Pig มาเชื่อมต่อกันในรูปของ Workflow ได้
- Hue ย่อมาจากคำว่า Hadoop User Experience เป็นเครื่องมือช่วยทำ User interface ของ Hadoop ให้ใช้งานได้ง่ายขึ้นกว่าการต้องใช้ command line
- Mahout เป็นเครื่องมือของ Data Scientist ที่ต้องการทำPredictive Analytics ข้อมูลบน Hadoop โดยใช้ภาษาจาวา ทั้งนี้ Mahout สามารถใช้ Algorithm ที่เป็น Recommender, Classification และ Clustering ได้
Hadoop 2.0
Hadoop เวอร์ชั่นแรกมีข้อจำกัดหลายประการอาทิเช่น ระบบการสำรองของ Secondary Master เป็นแบบ Passive และไม่สามารถทำ Multiple Master ได้จึงจำกัดเครื่อง Slave ไว้ไม่เกิน 4,000 เครื่อง และขัอสำคัญการประมวลผลต้องใช้ Map/Reduce ที่เป็นแบบ Batch ดังนั้นจึงมีการพัฒนา Hadoop 2.0 ที่จะลดข้อจำกัดต่างๆ Hadoop เวอร์ชั่นนี้จะมีสถาปัตยกรรมดังรูปที่ 4 โดยมีการนำ Data Opeating System ที่เรียกว่า YARN (Yet Another Resource Negotiator) เข้ามา
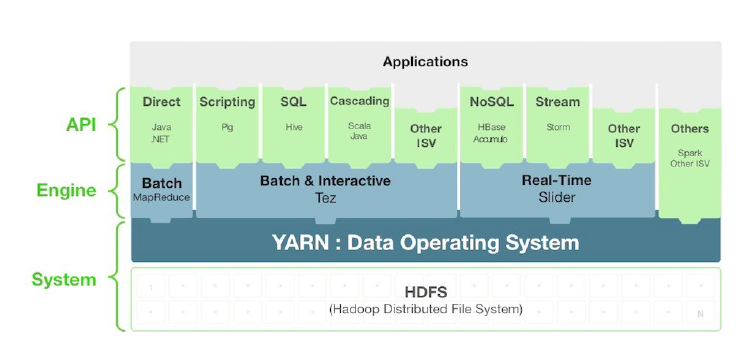
รูปที่ 4 : Hadoop 2.0
เราจะเห็นได้ว่าการมี YARN ทำให้เรามีวิธีการประมวลผลที่หลากหลายขึ้น ทั้งแบบ Batch อย่างเดิมที่ใช้ Map/Reduce หรือผ่าน Hive และก็เป็น Realtime ที่ใช้ Streaming หรือ MPI รวมถึงสามารถขยายจำนวนเครื่อง Slave ได้จำนวนมาก ในปัจจุบันมี่ Hadoop Distribution หลายตัวรวมทั้งที่เป็นผู้ให้บริการบน Cloud แบบ Hadoop as a Service ที่ใช้ Hadoop 2.0 จึงทำให้โอกาสการใช้งานของ Hadoop ในอนาคตจะขยายตัวมากขึ้นเรื่อยๆ
ธนชาติ นุ่มนนท์
IMC Institute
ตุลาคม 2557
