
ในตอนที่แล้ว ผมได้ระบุให้เห็นว่าการออกแบบสถาปัตยกรรม Big Data โดยใช้ Data Warehouse เพียงอย่างเดียวมีความไม่เหมาะสมอย่างไร เลยทำให้ในช่วงปี 2006 ได้มีการนำเทคโนโลยี Apache Hadoop มาใช้ในการทำหน้าเก็บและประมวลผลข้อมูลขนาดใหญ่ ที่เป็นหลักการของ Data Lake แทนที่ระบบของ Data Warehouse โดยมีสถาปัตยกรรมของระบบดังแสดงในรูปที่ 1
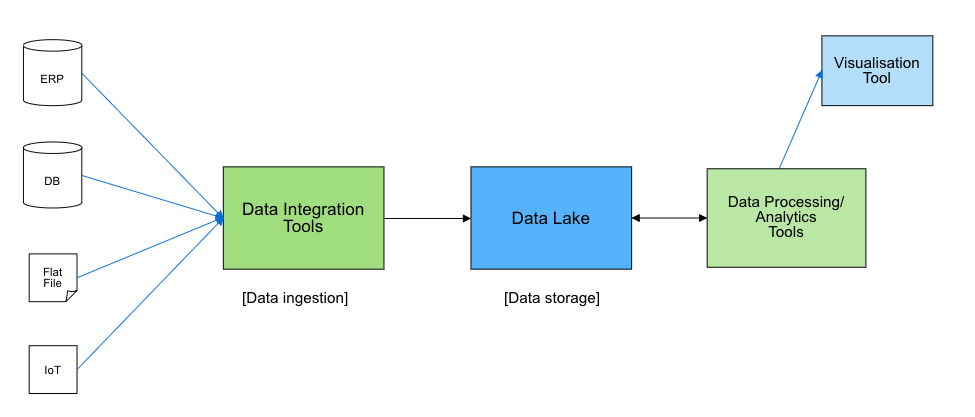
ทั้งนี้ Hadoop ที่เป็น Data Lake จะสามารถตอบโจทย์เรื่อง Big Data ตามคุณสมบัติต่างๆได้ดังนี้
- Volume เทคโนโลยี Hadoop มีสถาปัตยกรรมแบบกระจายที่ใช้ Commodity Hardware ซึ่งอาจจะเริ่มจากจำนวนเครื่องไม่มากนักและขยายไปเรื่อยๆได้ ทำให้สามารถเก็บข้อมูลได้เป็น Petabyte ในราคาที่ถูกกว่าเทคโนโลยี Data Warehouse มาก
- Variety เทคโนโลยี Hadoop สามารถเก็บข้อมูลได้หลากหลายชนิดทั้งที่เป็น structured data, semi-structured data และ unstructured data
- Velocity เทคโนโลยี Hadoop มีการประมวลผลได้หลายภาษา และสามารถที่จะใช้ประมวลผลข้อมูล streaming แบบ real-time หรือ Near real time ได้
นอกจากนี้ Apache Hadoop ยังมีเทคโนโลยีอื่นๆอีกจำนวนมากที่สามารถนำมาใช้งานร่วมกันได้ ทำให้การออกสถาปัตยกรรม Data Lake โดยใช้ Hadoop มีความสมบูรณ์ยิ่งขึ้น โดยเราสามารถที่จะเลือกใช้เทคโนโลยีต่างๆได้ดังนี้
- Data Ingestion: Sqoop, KafKa, NiFi, Flume, etc.
- Data Storage: Hadoop Distributed File System (HDFS)
- Data Processing / Data Analytic: Hive, Spark, Impala, Spark MLlib, etc.
- Data Visualisation: Tableau, Power BI, Qlik, etc.

เทคโนโลยีการประมวลผลของ Hadoop อย่าง Hive หรือ Spark หากจะนำไปแสดงผลโดยตรงยัง Data visualisation tool (ดังแสดงในรูปที่ 1) บางครั้งจะพบว่ามีความเร็วไม่พอ ดังนั้นเราจึงมักเห็นสถาปัตยกรรม Big data ที่นำเอา Data Warehouse (หรืออาจเป็น Database) มาเก็บข้อมูลไว้ก่อน (ดังแสดงในรูปที่ 2) เพื่อจะทำให้การทำ Query จาก Data visualisation tool มีความรวดเร็วขึ้น และจะแบ่งวิธีการวิเคราะห์ข้อมูล โดยการทำ BI จะใช้ข้อมูลที่อยู่ใน Data Warehouse ผ่านภาษา SQL ส่วนการทำ Data science ก็จะใช้ข้อมูลใน Data Lake ผ่านเครื่องมือต่างๆเช่น Spark MLlib เป็นต้น
แต่อย่างไรก็ตามการติดตั้ง Hadoop บนระบบ On-premise ก็ยังเป็นการลงทุนที่ค่อนข้างสูง จึงทำให้หลายๆโครงการในปัจจุบันเริ่มพิจารณาสถาปัตยกรรม Big data บนระบบ Cloud ซึ่งผมจะเขียนอธิบายในตอนต่อไป
ธนชาติ นุ่มมนท์
IMC Institute
