
ในตอนที่แล้วผมได้ระบุว่าการทำ Big Data ควรที่จะต้องออกแบบสถาปัตยกรรมโดยใช้ Data Lake เป็น Storage หลัก และเทคโนโลยีที่เหมาะกับการทำ Data Lake มากที่สุดก็คือ Hadoop แต่อย่างไรการจะติดตั้งระบบ Hadoop แบบ On-premise ยังมีข้อที่ควรจะพิจารณาอีกในหลายด้านดังนี้
- ระบบมีค่าใช้จ่ายด้าน Hadware และ Software เริ่มต้นที่ค่อนข้างสูง ซึ่งหากต้องการเก็บข้อมูลเป็นหลักสิบ Terabyte ค่าใช้จ่ายก็อาจเริ่มจากเป็นหลักสิบล้านบาท
- ระบบ Hadoop มีความซับซ้อนในการติดตั้ง และบำรุงรักษา
- ระบบ Hadoop จะไม่ได้แยกส่วนที่เป็น Storage และ Processing ออกจากกัน กล่าวคือระบบ Hardware เดียวกันจะถูกนำมาใช้งานในทั้งสองด้าน ทำให้ขาดความยืดหยุ่นและการลงทุนอาจไม่ได้ประสิทธิภาพนัก
- การจะขยายระบบ Hadoop จะไม่สามารถทำได้ทันทีทันใดเพราะจะมีขั้นตอนในการจัดหา Hardware เพิ่มเติม
- ระบบ Hadoop มีเทคโนโลยีในการประมวลผลที่ซับซ้อน และมีความหลากหลายทำให้นักพัฒนาต้องเรียนรู้หลากหลายระบบ และแม้แต่เพียงแค่การจะเข้าดูข้อมูลที่เก็บไว้ในระบบก็ไม่ง่ายนัก
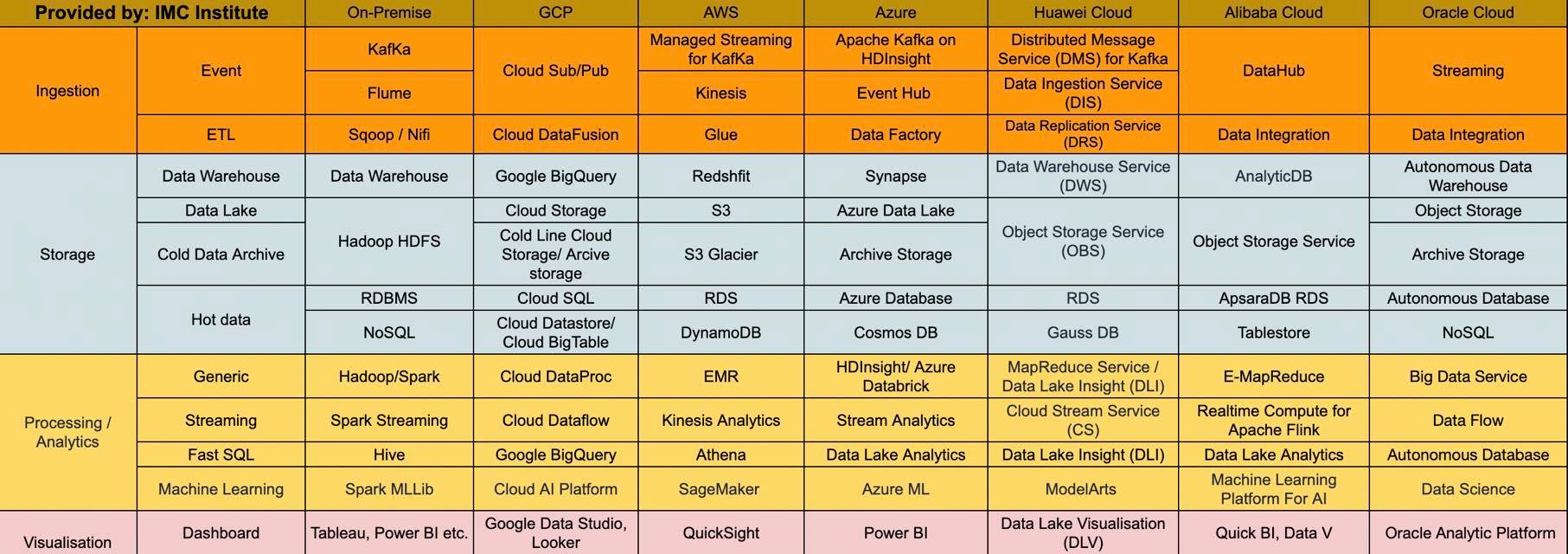
จากข้อจำกัดข้างต้นทำให้หลายๆองค์กรหันมาสนใจสถาปัตยกรรม Big data แบบที่ใช้บริการต่างๆของ Public cloud ค่ายดังๆอาทิเช่น Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), Oracle cloud, Huawei Cloud และ Alibaba Cloud เป็นต้น เนื่องจาก Public cloud เหล่านี้มีบริการที่เกี่ยวข้องกับ Big Data มากมาย อาทิเช่น
- Cloud storage service อย่าง AWS S3, Azure data lake Storage, Google cloud storage หรือ Object storage service ของ Huawei Cloud
- Database service อย่าง RDS ของ AWS, Azure SQL, Cloud SQL ของ GCP, ApsaraDB RDS ของ Alibaba Cloud หรือ Autonomous database ของ Oracle cloud
- Data warehouse service อย่าง Redshift ของ AWS, Azure Synapse, Google BigQuery, Huawei DWS, Alibaba AnalyticDB หรือ Autonomous data warehouse ของ Oracle cloud
- Hadoop/Spark service อย่าง EMR ของ AWS, HDInsight หรือ Databrick ของ Azure, DataProc ของ GCP, MapReduce service หรือ Data Lake Service ของ Huawei Cloud
ผมได้เขียนสรุปตัวอย่างบริการต่างๆที่ Public cloud ทั้งหกรายนี้มีเมื่อเทียบกับระบบ Big data แบบ On-premise ดังตารางข้างล่างนี้
จุดเด่นของการออกแบบสถาปัตยกรรม Big Data บน Public cloud เมื่อเทียบกับระบบ On-premise มีดังนี้
- มีทรัพยากรที่ยืดหยุ่นกว่า (Elastic resources) กล่าวคือบริการต่างๆบน Cloud สามารถจะลดหรือขยายได้อย่างรวดเร็ว เช่นการเพิ่มขนาดการเก็บข้อมูล หรือเพิ่มจำนวน Server
- Modularity กล่าวคือบริการแต่ละตัวเป็นอิสระต่อกัน ดังนั้นจึงมีการแยกระบบ Storage และ Processing โดยไม่ได้ผูกไว้กับระบบ Hardware ชุดเดียวกันเหมือน Hadoop แบบ On-premise
- ค่าใช้จ่ายขึ้นอยู่กับการใช้งาน และไม่ต้องเสียค่าลงทุนเริ่มต้นสูงนัก
- สามารถเริ่มทำโครงการได้อย่างรวดเร็ว เพราะบริการต่างๆบน Public cloud มีอยู่แล้ว สามารถเริ่มต้นโครงการได้ทันที
- การใช้บริการ Cloud เริ่มเป็น New normal สำหรับการทำระบบไอที และมีบริการใหม่ๆทางด้าน Big data และ AI ที่สามารถทำให้เราสร้างนวัตกรรมในเรื่องต่างๆได้ง่ายขึ้น
แต่การจะใช้บริการบน Public cloud จำเป็นจะต้องออกแบบสถาปัตยกรรมให้ถูกต้องและเลือกบริการให้เหมาะสม ซึ่งผมจะเขียนอธิบายในตอนต่อไป
ธนชาติ นุ่มนนท์
IMC Institute
