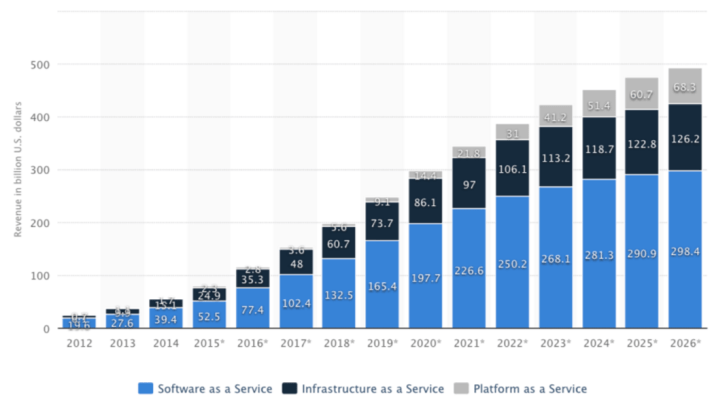
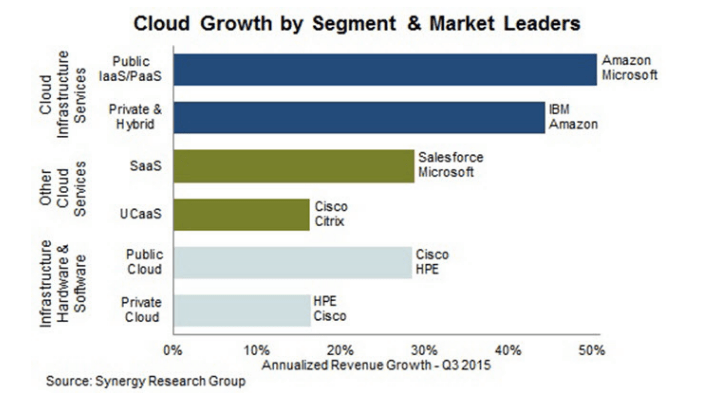
การนำข้อมูลขนาดใหญ่ไปใช้งานจริงๆ ยังมีไม่มากนัก ทั้งนี้ด้วยข้อจำกัดในเรื่องของเทคโนโลยีและจำนวนบุคลากรที่มีความสามารถ ซึ่งทางสมาคม PIKOM ของมาเลเซียได้ทำรายงานเรื่อง Global Business Services Outlook Report 2015 ชี้ให้เห็นผลกระทบของเทคโนโลยีด้าน Big Data ในประเทศกลุ่ม APAC และอุตสาหกรรมต่างๆ โดยสรุปมาเป็นตารางดังนี้
ตารางที่ 1 ระดับผลกระทบของเทคโนโลยี Big Data [แหล่งข้อมูลจาก PIKOM]

ซึ่งจะเห็นได้ว่ากลุ่มอุตสาหกรรมที่มีผลกระทบต่อการประยุกต์ใช้เทคโนโลยี Big Data อย่างมากคือ อุตสาหกรรมด้านการเงินการธนาคาร (BFSI) ด้านโทรคมนาคม ด้านค้าปลีกรวมถึงพาณิชย์อิเล็กทรอนิกส์ (E-commerce) และด้านสุขภาพ ส่วนกลุ่มภาครัฐบาลและกลุ่มอุตสาหกรรมการผลิตมีผลกระทบปานกลาง สำหรับประเทศที่มีการประยุกต์ใช้ Big Data อย่างมากคือสหรัฐอเมริกาและสหราชอาณาจักร โดยประเทศญี่ปุ่น สิงคโปร์ และออสเตรเลียมีผลกระทบการประยุกต์ใช้งานปานกลาง ส่วนประเทศไทยอยู่ในกลุ่มที่เหลือที่ยังมีการประยุกต์ใช้งานน้อย
สำหรับตัวอย่างของการนำเทคโนโลยี Big Data มาใช้งานในภาคอุตสาหกรรมต่างๆ มีดังนี้
- อุตสาหกรรมค้าปลีก อาจนำมาเพื่อวิเคราะห์ความต้องการของลูกค้า เพื่อทำให้เห็นข้อมูลของลูกค้ารอบด้าน (Customer 360) หรือการแบ่งกลุ่มลูกค้า (Customer Segmentation) นำมาจัดแผนการตลาด สร้างแคมเปญตอบสนองต่อพฤติกรรมการอุปโภค บริโภค ที่ปรับเปลี่ยนอยู่ตลอดเวลา ให้ดึงดูดลูกค้าเข้ามาจับจ่ายใช้สอยมากที่สุด ในสภาพการแข่งขันที่สูง และมีช่องทางอื่นๆ ใหม่ๆ เข้ามาเป็นทางเลือกมากขึ้น
- อุตสาหกรรมโทรคมนาคม อาจนำเพื่อใช้ในการวิเคราะห์เครือข่ายโทรศัพท์เคลื่อนที่ วิเคราะห์การใช้งานของลูกค้า การวิเคราะห์แนวโน้มการย้ายค่ายของลูกค้า (Customer Churn) และนำเอาข้อมูลไปต่อยอดเพิ่มการให้บริการอีกมากมาย อีกทั้งยังสามารถนำข้อมูลมาวิเคราะห์ เรื่องความมั่นคงปลอดภัย ให้เป็นประโยชน์กับลูกค้าและเพื่อสาธารณะได้อีกด้วย
- อุตสาหกรรมการเงิน อาจนำมาเพื่อวิเคราะห์การฉ้อโกงเงิน การคาดการณ์ความต้องการของลูกค้า การแบ่งกลุ่มลูกค้า และการวิเคราะห์ความเสี่ยงของลูกค้า
- ด้านวิทยาศาสตร์และเทคโนโลยีเช่น การพยากรณ์อากาศ การคาดการณ์ข้อมูลน้ำ หรือการวิเคราะห์ข้อมูลจากเซ็นเซอร์ต่างๆ การใช้งานพลังงาน
- งานด้านการตลาด อาจนำมาเพื่อวิเคราะห์ข้อมูลจากเครือข่ายสังคมออนไลน์ (Social Media) การวิเคราะห์ข้อมูลที่พูดถึงสินค้าหรือแบรนด์ของหน่วยงาน (Sentiment Analysis) การค้นหาลูกค้าใหม่ๆ บนโลกออนไลน์
- งานด้านบันเทิง หรือการท่องเที่ยว เป็นการวิเคราะห์กระแส ความนิยม talk of the town ในแต่ละกลุ่มบริการซึ่งมีส่วนเกี่ยวโยงกับ ข้อมูล ความคิดเห็น ในโซเชียลมีเดีย เป็นส่วนใหญ่ เพื่อจัดโปรแกรมหรืองาน ที่สร้างความสนใจให้ได้ตรงกับความสนใจของตลาด ในแต่ละช่วง แต่ละเวลา กับกลุ่มเป้าหมายที่ต่างกันไป
การประยุกต์ใช้งาน Big Data ในภาครัฐ
สำหรับตัวอย่างการใช้ประยุกต์ใช้งาน Big Data ในภาครัฐสามารถนำมาใช้งานได้ในหลายๆ หน่วยงานเช่น ด้านสาธารณสุข ด้านวิทยาศาสตร์ ด้านความมั่นคง ด้านการเงิน ด้านการบริการประชาชน ด้านเกษตรกรรม ด้านสาธารณูปโภค หรือด้านคมนาคม อาทิเช่น
- การใช้เพื่อวิเคราะห์ข้อมูลอุตุนิยมวิทยาในการพยากรณ์อากาศ
- การใช้เพื่อวิเคราะห์ข้อมูลการจราจร
- การวิเคราะห์ข้อมูลเพื่อลดปัญหาและป้องกันการเกิดอาชญากรรม
- การวิเคราะห์ข้อมูลด้านสาธารณสุข เช่น แนวโน้มของผู้ป่วย การรักษาพยาบาล หรือการเกิดโรคระบาด
- การวิเคราะห์ข้อมูลด้านน้ำ แหล่งน้ำ ปริมาณฝน และการใช้น้ำ
- การวิเคราะห์ข้อมูลการใช้ไฟฟ้า ค่าการใช้พลังงาน
- การวิเคราะห์ข้อมูลการทหารและความมั่นคงต่างๆ
- การวิเคราะห์ข้อมูลเพื่อตรวจสอบการเสียภาษีของประชาชนหรือบริษัทห้างร้านต่างๆ
ข้อดีของการประยุกต์ใช้เทคโนโลยี Big Data ในภาครัฐสามารถสรุปได้ดังนี้
- การใช้เงินงบประมาณและเงินรายได้ต่างๆ ของภาครัฐจะมีประสิทธิภาพมากขึ้น เพราะ Big Data จะช่วยคาดการณ์และวิเคราะห์ได้แม่นยำมากขึ้น
- ภาครัฐสามารถที่จะตรวจสอบข้อมูลการใช้งบประมาณได้ดียิ่งขึ้น
- ภาครัฐจะมีรายได้มากขึ้นหากมีการนำ Big Data มาใช้วิเคราะห์ข้อมูลการเสียภาษีด้านต่างๆ ว่ามีความถูกต้องเพียงใด
- ประชาชนจะได้รับการบริการที่ดีขึ้น เช่นการนำมาแก้ปัญหาจราจร การให้บริการสาธารณสุข การให้บริการสาธารณูปโภค
- ประชาชนจะมีคุณภาพชีวิตที่ดีขึ้น เช่นเพิ่มความปลอดภัยโดยการวิเคราะห์แนวโน้มอาชญากรรม การมีสุขภาพที่ดีขึ้นจากการวิเคราะห์ข้อมูลสาธารณสุข
- เกิดความร่วมมือกับภาคเอกชนมากขึ้น จากการนำข้อมูลไปใช้
- จะมีข้อมูลใหม่ๆ มากขึ้นจากประชาชน (Crowdsourcing) หรือข้อมูลจากอุปกรณ์ Internet of Things
- เป็นการสร้างทักษะและผู้เชี่ยวชาญด้านข้อมูลมากขึ้น
อย่างไรก็ตามความท้าทายของการประยุกต์ใช้เทคโนโลยี Big Data ยังอยู่ที่ความร่วมมือของหน่วยงานต่างๆ โดยอาจสรุปปัญหาต่างๆ ที่ควรแก้ไขดังนี้
- วัฒนธรรมของหน่วยงานจำนวนมากที่จะรู้สึกหรือคิดว่าข้อมูลเป็นของหน่วยงานตนเอง โดยไม่มีการแชร์ข้อมูลให้กับหน่วยงานภายนอกหรือหน่วยงานอื่นในองค์กรเดียวกัน
- คุณภาพของข้อมูลที่อาจไม่สมบูรณ์หรือขาดความถูกต้อง
- ปัญหาเรื่องข้อมูลที่เป็นสิทธิส่วนบุคคล หรือความเท่าเทียมกันของการเข้าถึงข้อมูลของภาคประชาชน
- การขาดบุคลากรที่มีความสามารถทางด้านเทคโนโลยี Big Data
ดังนั้นสิ่งที่ภาครัฐควรจะต้องเร่งทำเพื่อให้มีการประยุกต์ใช้ Big Data ในองค์กรคือ
- พัฒนาความรู้ความเข้าใจในการประยุกต์ใช้เทคโนโลยี Big Data และสร้างวัฒนธรรมการร่วมมือการแชร์ข้อมูล
- ออกกฎหมายหรือกฎระเบียบเพื่อให้เกิดการเปิดข้อมูลของภาครัฐ (Open Data)
- พัฒนาทักษะบุคลากรให้มีความรู้ด้านเทคโนโลยี Big Data
- มีหน่วยงานกลางที่ให้บริการเทคโนโลยี Big Data เพื่อไม่ให้เกิดการลงทุนซ้ำซ้อน และไม่ควรให้ทุกหน่วยงานลงทุนซื้อเทคโนโลยีมากเกินไป
ธนชาติ นุ่มนนท์
IMC Institute
มิถุนายน 2559