Hadoop เป็นเทคโนโลยีทางด้าน Big Data ที่น่าสนใจเพราะสามารถที่จะเก็บข้อมูลที่เป็น Unstructure จำนวนเป็น PetaByte ได้ ซึ่งในทางทฤษฎีการศึกษาการติดตั้งระบบ Hadoop และการนำมา Hadoop มาใช้ในการวิเคราะห์ข้อมูลโดยใช้โปรแกรมอย่าง MapReduce หรือใช้เทคโนโลยีต่างๆอย่าง Hive, Pig, Scoop หรือ HBase เป็นเรื่องไม่ยากนัก แต่ในทางปฎิบัติปัญหาสำคัญที่องค์กรจะพบในการติดตั้ง Hadoop Big Data ก็คือการหาเครื่อง Server จำนวนมากมาเพื่อติดตั้งระบบ Hadoop Cluster จำนวนตั้งแต่ 5 เครื่องไปจนเป็นร้อยเป็นพันเครื่อง
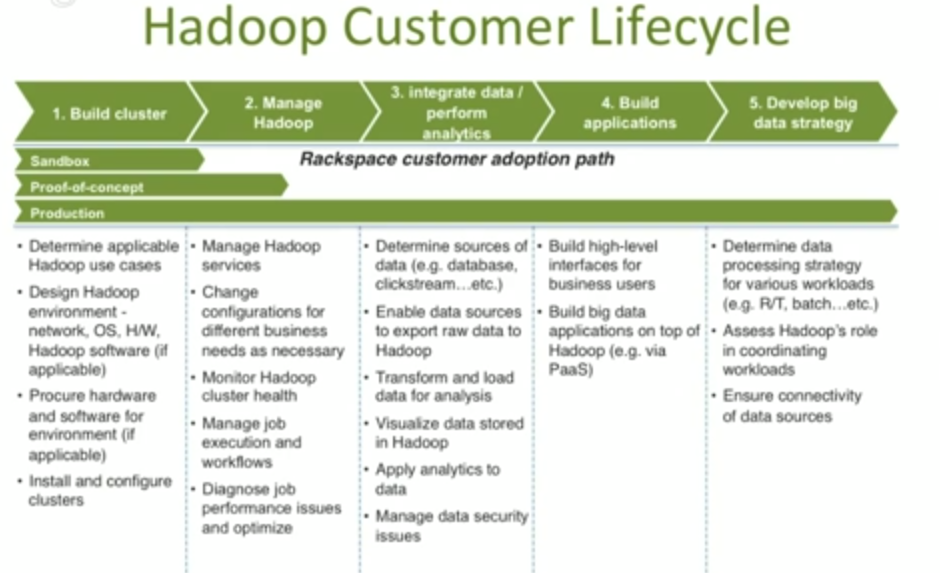
รูปที่ 1 Hadoop Lifecycle [Source: Rackspace]
การแก้ปัญหาในเรื่องการจัดหา Server อาจทำได้โดยการใช้ระบบ Public Cloud ซึ่งก็จะเป็นการลดค่่าใช้จ่ายขององค์กร ทั้งนี้รูปแบบของการใช้ Hadoop บน Public Cloud มีสองแบบคือ
- ติดตั้ง Hadoop Cluster โดยใช้ Virtual Server ในระบบ Public IaaS Cloud อย่าง Amazon Web Services (AWS) หรือ Microsoft Azure กรณีนี้จะใช้ในกรณีที่เราจะต้องการนำ Hadoop มาใช้ในการเก็บข้อมูลขนาดใหญ่โดยใช้ HDFS และใช้ในการวิเคราะห์ข้่อมูลโดยใช้เครื่องมืออย่าง MapReduce, Hive, Pig
- การใช้บริการ Hadoop as a Service ของ Public Cloud Provider ที่ได้ติดตั้งระบบ Hadoop ไว้แล้ว และเราต้องการใช้ระบบที่มีอยู่เช่น MapReduce, Hive, Pig มาใช้ในการวิเคราะห์ข้อมูล ทั้งนี้ข้อมูลที่จะนำมาวิเคราะห์อาจอยู่ในองค์กรเราหรือเก็บไว้ที่อื่น
การใช้ Public Cloud ในกรณีที่ 1 ถ้ามีข้อมูลขนาดใหญ่มาก ก็อาจจะมีค่าใช้จ่ายที่สูง ยิ่งถ้ามีจุดประสงค์เพื่อที่จะใช้ในการเก็บข้อมูลแบบ Unstructure ก็ดูอาจไม่คุ้มค่านัก แต่ก็มีข้อดีที่มีระบบ Hadoop Cluster ที่ติดตั้งเองและไม่ต้องใช้ร่วมกับคนอื่น ผู้เขียนเองเคยทดลองติดตั้งระบบแบบนี้โดยใช้ Azure HDInsight และทดลองติดตั้ง Hadoop CloudEra Distribution ลงใน AWS EC2 และล่าสุดทดลองติดตั้ง Apache Hadoop Cluster 4 เครื่องลงบน AWS EC2
สำหรับกรณีที่ 2 น่าจะเหมาะกับผู้ต้องการวิเคราะห์ข้อมูลขนาดใหญ่เช่น ข้อมูลที่เป็น Text หรือ ข้อมูลจาก Social Media โดยใช่้เทคโนโลยี Hadoop โดยไม่ต้องการลงทุนซื้อเครื่อง Server และก็ไม่ได้เน้นที่จะใช้ Hadoop Cluster ในการเก็บข้อมูลอย่างถาวร ในปัจจุบันมีผู้ให้บริการ Cloud Computing อยู่่หลายรายที่ให้บริการ Hadoop as a Service โดยจะคิดค่าบริการตามระยะเวลาที่ใช้ในการประมวลผล และอาจรวมถึงขนาดของข้อมูล การใช้ Bandwidth ตัวอย่างของผู้ให้บริการมีดังนี้
- Amazon Elastic Map Reduce
เป็นบริการ Hadoop Cluster ของ AWS ที่ผู้ใช้บริการสามารถที่จะเลือกขนาดของ Cluster หรือภาษาที่จะใช้การวิเคราะห์ข้อมูลเช่น Java สำหรับ MapReduce หรือ Python สำหรับ Streaming และ Hive, Pig ผู้เขียนเองเคยใช้ AWS EMR ในการวิเคราะห์ข้อมูลดยการ Transfer ข้อมูลผ่าน Amazon S3 ก็สะดวกและใช้งานง่าย ทั้งนี้ Hadoop Distribution ที่ลงบน EMR ผู้ใช้สามารถเลือกได้ระหว่าง Amazon หรือ MapR Distribution
รูปที่ 2 ตัวอย่างการใช้ Amazon EMR
- Rackspace Cloud Big Data Platform
Rackspace หนึ่งในผู้นำด้าน Public IaaS Cloud มีบริการที่เรียกว่า Hadoop as a Service เพื่อให้ผู้ใช้สามารถที่จะส่งข้อมูลมาประมวลผลได้ โดยได้ร่วมมือกับ Hortonworks ในการติดตั้ง Distribution ของ Hadoop
 รูปที่ 3 Rackspace Big Data
รูปที่ 3 Rackspace Big Data
- Qubole
Qubole เป็นผู้ให้บริการ Hadoop as a Service โดยเฉพาะ ซึ่งทางบริษัทนี้ติดตั้ง Hadoop Cluster บนเครื่อง Server ของ AWS และ Google Compute Engine คิดค่าบริการ Data Service ในการวิเคราะห์ข้อมูลทั้งแบบเหมาจ่ายรายเดือน (เริ่มตั้งแต่ $5,900 ต่อเดือน) และตามการใช้งาน ($0.11 ต่อ Computing Hour และ $0.22 ต่อ import/export)

รูปที่ 4 Qubole.com
- Google Cloud Platform
Google มีระบบ Apache Hadoop ที่รันอยู่บน Google Cloud ให้ผู้ใช้สามารถประมวลข้อมูลโดยใช้ MapReduce, Hadoop Streaming, Hive หรือ Pig ที่เก็บอยู่บน Google Cloud Storage ได้ โดยคิดค่าใช้จ่ายตามปริมาณการใช้งาน

รูปที่ 5 Google Apache Hadoop
- IBM Bluemix: Analytic on Hadoop
IBM Bluemix ซึ่งเป็น Public PaaS ก็มีการติดตั้ง Hadoop Cluster เพื่อให้ผู้ใช้สามารถประมวลผลข้อมูลขนาดใหญ่โดยใช้ MapReduce, Hive หรือ Pig เช่นเดียวกับ Google หรือ AWS ทั้งนี้ Hadoop ที่ติดตั้งบน Bluemix เป็น Distribution ของ IBM ที่ชื่อ InfoSphere BigInsights
รูปที่ 6 IBM Analytics fo Hadoop
จากที่กล่าวมาทั้งหมดนี้จะเห็นได้ว่า ในปัจจุบันองค์กรต่างๆสามารถทำการประมวลผลข้อมูลโดยใช้ เทคโนโลยี Hadoop ได้เลยผ่านบริการ Public Cloud โดยไม่ต้องจัดหาเครื่อง Server หลายๆองค์กรก็อาจจะห่วงเรื่องความปลอดภัยของข้อมูล ซึ่ีงในกรณีของ Hadoop as a Service เราไม่จำเป็นต้องเก็บข่้อมูลลงใน Hadoop Cluster โดยเราสามารถ Transfer ข้อมูลที่จำเป็นในการประมวลผลไปใช้ได้เป็นครั้งคราวไป ทำให้เราน่าจะเชื่อมั่นในเรื่องข้อมูลได้ดีขึ้น ข้อสำคัญเราจะเห็นว่ามีองค์กรใหญ่ๆจำนวนมากมาใช้บริการแบบนี้ ซึ่งแน่นอนข้อมูลขององค์กรเหล่านั้นก็มีความสำคัญไม่น้อยกว่าของเรา จึงทำให้เห็นได้ว่าองค์กรต่างๆมีความเชื่อมั่นในบริการแบบนี้มากขึ้นเรื่อยๆ
ธนชาติ นุ่มนนท์
IMC Institute
กันยายน 2557

1 ความคิดเกี่ยวกับ "Big Data on Cloud ตอนที่ 1: Hadoop as a Service"