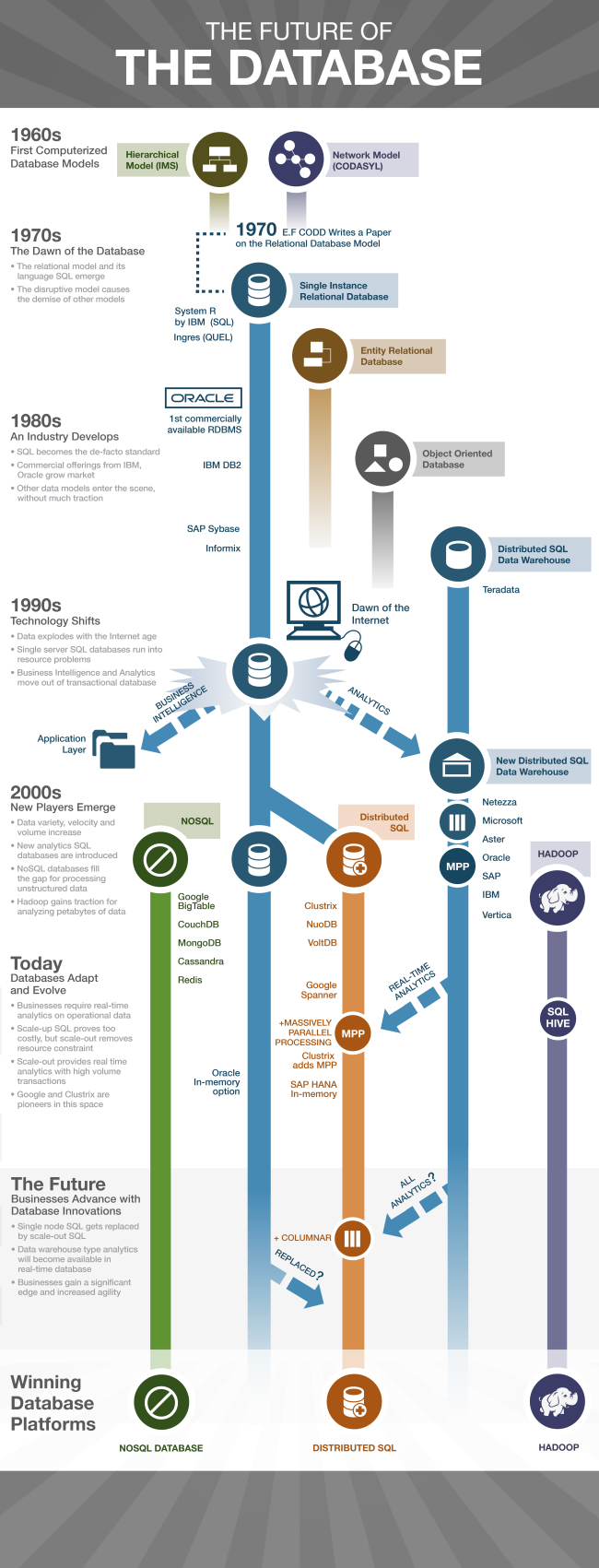
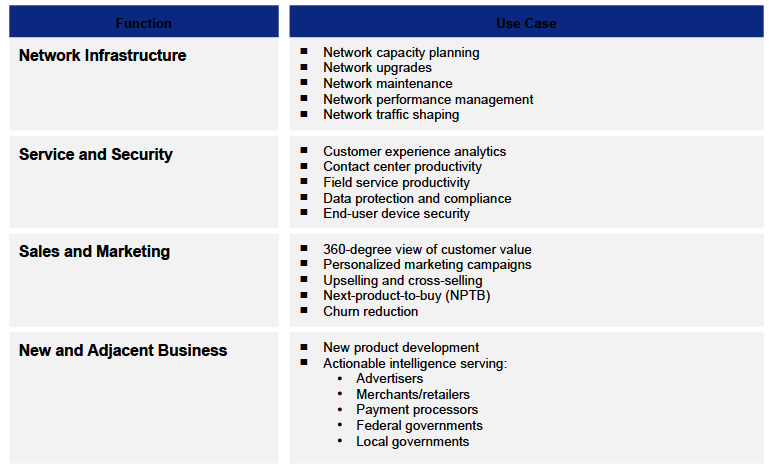
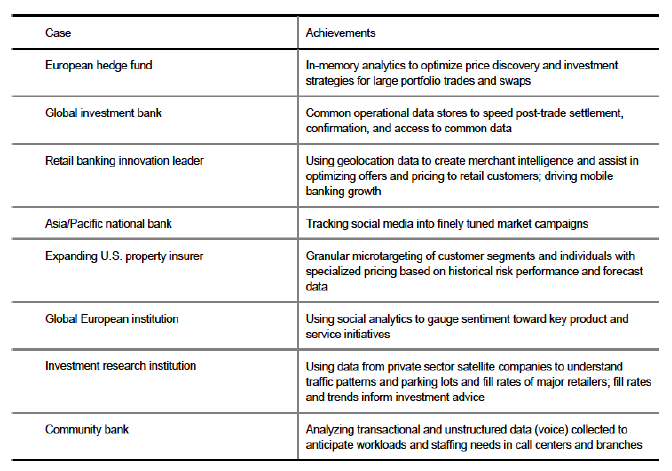
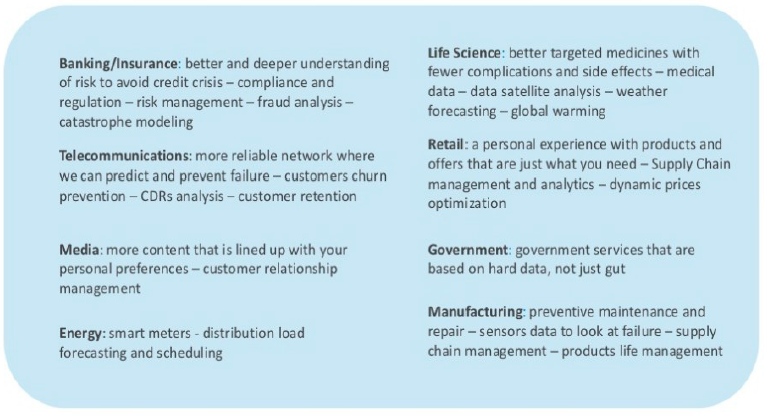
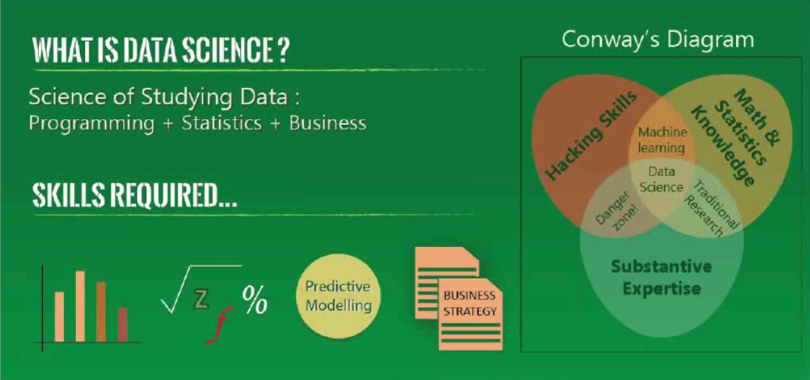
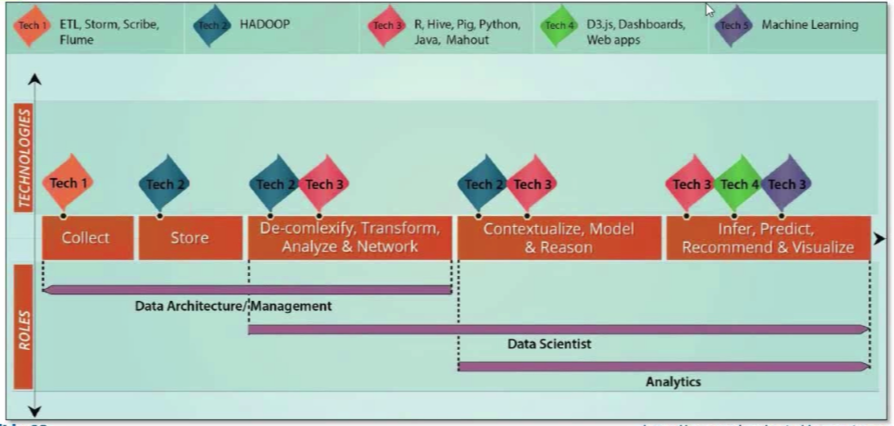
ผมไม่ได้เขียนบล็อกมาสองเดือนกว่า เพราะยุ่งอยู่กับการศึกษาเรื่อง Big Data เตรียมการสอนและเปิดหลักสูตรใหม่ๆอาทิเช่น
- เปิดหลักสูตร Big Data Certification จำนวน 120 ชั่วโมงที่มีผู้เข้าร่วมอบรมกว่า30 คน
- เปิดหลักสูตร Introduction to Data Science เมื่อต้นเดือนเมษายน ก็เน้นสอนเรื่องของ Hadoop, R และ Mahout ในการทำ Machine Learning รุ่นแรกมีคนเช้ามาเรียน 20 กว่าท่าน
- ปรับปรุงเนื้อหาหลักสูตร Big Data using Hadoop Workshop โดยมีการนำ Cloud Virtual Server ของ AWS มาใช้ในการอบรม และเปิดอบรมรุ่นแรกของปีนี้เมื่อปลายเดือนมีนาคม มีคนอบรม 30 คน
- ปรับปรุงเนื้อหา Big Data Programming using Hadoop for Developer โดยมีการเน้นการใช้ Cluster ขนาดใหญ่บน Amazon EMR มากขึ้น และเปิดอบรมไปเมื่อเดือนกุมภาพันธ์
- จัดฟรีสัมมนา Big Data User Group แก่บุคคลทั่วไปเพื่อให้เข้าใจเรื่อง Big Data Analytics โดยจัดไปเมื่อต้นเดือนมีนาคม
- เปิด Hadoop Big Data Challenge เพื่อคนทั่วไปสามารถมาทดลองวิเคราะห์ข้อมูลขนาดใหญ่บน Hadoop Cluster ที่รันอยู่บน AWS จำนวนกว่า 40 vCPU
จากการทำงานด้านนี้ในช่วงสองเดือนที่ผ่านมา ทำให้ได้ประส[การณ์และข้อมูลใหม่ๆพอควร โดยเฉพาะประสบการณ์การติดตั้ง Hadoop หรือ NoSQL บน Public Cloud ซึ่งข้อดีของการใช้ Public Cloud คือเราไม่ต้องจัดหา Server ขนาดใหญ่จำนวนมาก และสามารถ Provision ระบบได้อย่างรวดเร็ว แต่มีข้อเสียคือค่าใช้จ่ายระยะยาวจะแพงกว่าการจัดหา Server เอง และถ้ามีข้อมูลจำนวนมากที่ต้อง Transfer ไปอาจไม่เหมาะสมเพราะจะเกิดความล่าช้า นอกจากนี้ยังอาจมีปัญหาเรื่องความปลอดภัยของข้อมูล
แต่การใช้ Public Cloud จะเหมาะมากกับการใช้งานเพื่อเรียนรู้ หรือการทำ Development หรือ Test Environment นอกจากนี้ยังมีบางกรณีที่การใช้ Public Cloud มาทำ Big Data Analytics อาจมีความเหมาะสมกว่าการจัดหา Server ขนาดใหญ่มาใช้งานเอง อาทิเช่น
- กรณีที่ระบบปัจจุบันขององค์กรทำงานอยู่บน Public Cloud อยู่แล้ว อาทิเช่นมีระบบ Web Application ที่รันอยู่บน Azure หรือมีระบบอยู่ Salesforce.com
- กรณีที่ข้อมูลที่ต้องการวิเคราะห์ส่วนใหญ่เป็นข้อมูลภายนอกที่อยู่บน Cloud เช่นการวิเคราะห์ข้อมูลจาก Facebook ที่การนำข้อมูลขนาดใหญ่เหล่านั้นกลับมาเก็บไว้ภายในจะทำให้เปลืองเนื้อที่และล่าช้าในการโอนย้ายข้อมูล
- กรณีที่มีโครงการเฉพาะด้านในการวิเคราะห์ข้อมูลขนาดใหญ่เพียงครั้งคราว ซึ่งไม่คุ้มค่ากับการลงทุนจัดหาเครื่องมาใช้เอง
การใช้ Public Cloud สำหรับการวิเคราะห์ข้อมูลโดยใช้ Hadoop หรือ NoSQL มีสองรูปแบบคือ
1) การใช้ Virtual Server ในการติดตั้ง Middleware อาทิเช่นการใช้ EC2 ของ AWS หรือ Compute Engine ของ Google Cloud มาลงซอฟต์แวร์ ข้อดีของวิธีการนี้คือเราสามารถเลือกซอฟต์แวร์มาติดตั้งได้ เสมือนกับเราจัดหา Server มาเอง และสามารถควบคุมการติดตั้งได้ ที่ผ่านมาผมได้เขียนแบบฝึกหัดที่ติดตั้งระบบแบบนี้อยู่หลายแบบฝึกหัดดังนี้
- Big Data using Hadoop ที่ใช้ Amazon EC2
- Mahout Workshop on Google Cloud Platform ที่ใช้ Google Compute Engine
- Setup Hadoop Cluster on Amazon EC2
- Running Cassandra on Amazon EC2
2) การใช้ PaaS ที่อาจเป็น Hadoop as a Service หรือ NoSQL as a Service ซึ่งในปัจจุบัน Public Cloud รายใหญ่ๆทุกค่ายจะมีระบบอย่างนี้ เช่น EMR สำหรับ Hadoop และ Dynamo DB สำหรับ NoSQL บน AWS หรือค่ายอย่าง Microsoft Azure ก็มี HDInsight สำหรับ Hadoop และ DocumentDB สำหรับ NoSQL ข้อดีของระบบแบบนี้คือ เราจ่ายตามการใช้งานไม่ต้องรัน Server ไว้ตลอด, ติดตั้งง่ายเพราะผู้ให้บริการ Cloud ลงระบบมาให้แล้ว แต่ข้อเสียก็คือเราไม่สามารถปรับเปลี่ยนซอฟต์แวร์ที่ติดตั้งได้เอง อาทิเช่น Hadoop ที่อยู่บน EMR มีให้เลือกแค่ Amazon Distribution หรือ MapR Distribution ผมเองก็ได้เขียนแบบฝึกหัดlสำหรับการใช้ Amazon EMR ไว้ดังนี้
สำหรับผู้ที่ต้องการศึกษาการติดตั้ง Hadoop Cluster ผมอาจแนะนำให้ใช้ Google Cloud Platform ครับ เพราะระบบมีให้ทดลองใช้ 60 วัน โดยเราสามารถที่จะลองใช้ Compute Engine ขนาด 4 vCPU ได้ (ดูขั้นตอนการติดตั้ง Hadoop บน Google Cloud ตามนี้) และถ้าต้องการใช้ Hadooo[ as a Service ผมแนะนำให้ใช้ Amzon EMR ตามแบบฝึกหัดข้างต้น แต่ก็มีค่าใช่จ่ายในการรันแต่ละครั้ง
วันนี้ขอแค่นี้ครับและอาจเขียนออกเป็นเทคนิคมากหน่อยครับ เพราะไม่ได้เขียนบล็อกมาหลายสัปดาห์ มัวแต่ไปเขียนแบบฝึกหัดที่เป็นด้านเทคนิคให้ผู้เข้าอบรมได้เรียนกัน
ธนชาติ นุ่มนนท์
เมษายน 2558