เมื่อพูดถึง Big Data หลายๆคนก็คงเริ่มเข้าใจความหมายของ 3Vs (Volume, Velocity, Variety) และเริ่มที่จะเห็นภาพว่าข้อมูลจะมีขนาดใหญ่ขึ้นและมีหลากหลายรูปแบบ ดังนั้นจึงไม่แปลกใจที่หลายองค์กรจำเป็นต้องปรับ Information Infrastructure เพื่อให้รองรับกับการบริหารจัดการ Big Data ได้
เทคโนโลยีฐานข้อมูลเดิมที่เป็น RDBMS และภาษา SQL ก็ยังคงอยู่แต่การที่จะนำมาใช้ในการเก็บข้อมูลขนาดใหญ่มากๆเป็นหลายร้อย TeraByte หรือนับเป็น PetaByte อาจไม่สามารถทำได้และอาจมีต้นทุนที่สูงเกินไป และยิ่งถ้าข้อมูลเป็นแบบ Unstructure ก็คงไม่สามารถจะเก็บได้ นอกจากนี้การจะประมวลผลข้อมูลหลายร้อยล้านเรคอร์ดโดยใช้เทคโนโลยี RDBMS ผ่านภาษา SQL ก็อาจใช้เวลานานและบางครั้งอาจไม่สามารถประมวลผลได้
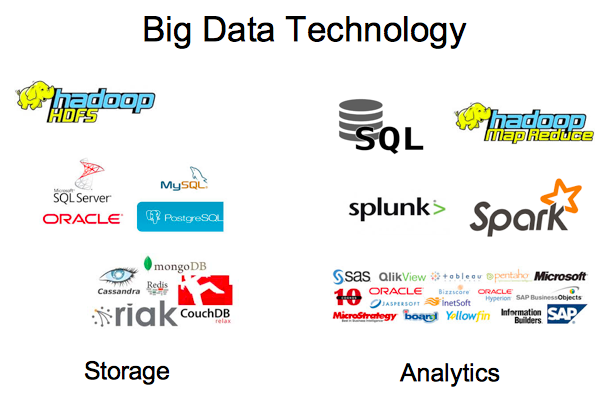
รูปที่ 1 ตัวอย่างของ Big Data Technology
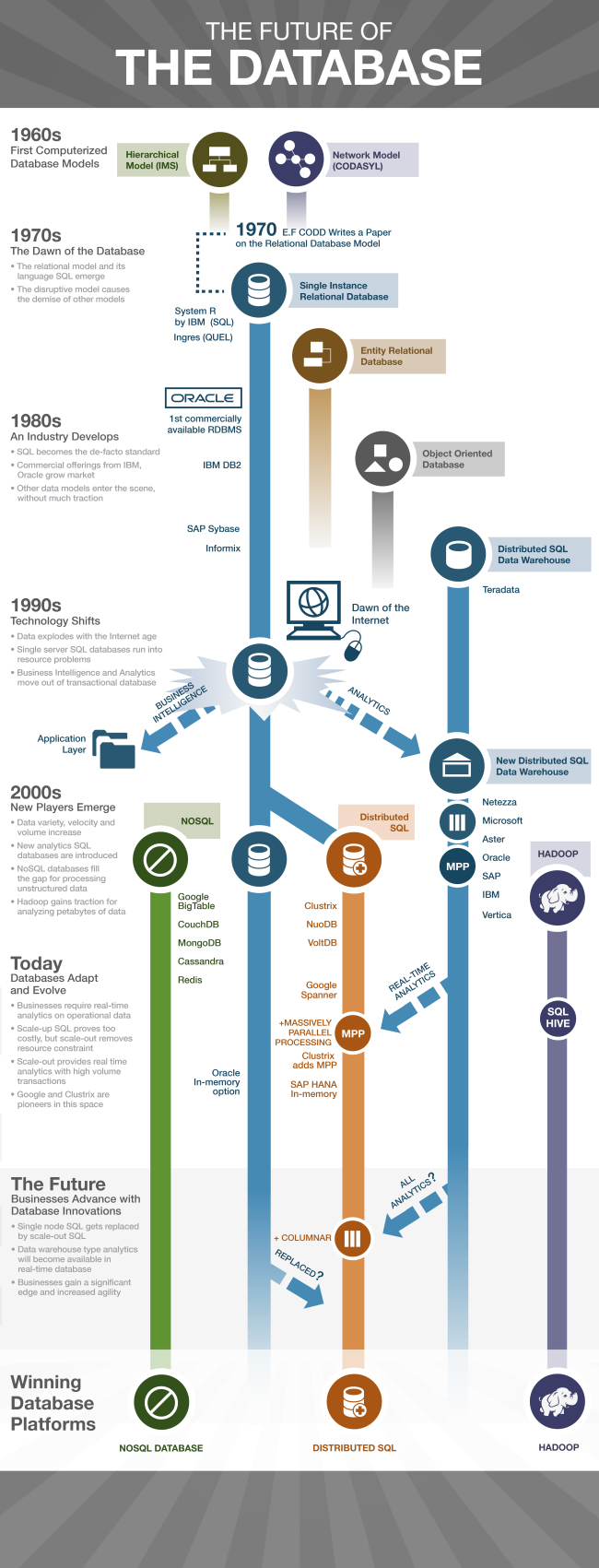
ด้วยเหตุนี้จึงเริ่มมีการคิดถึงเทคโนโลยีอื่นๆในเก็บและประมวลผลข้อมูลที่เป็น Big Data ดังที่ได้แสดงตัวอย่างในรูปที่ 1 ซึ่งหากเราแบ่งเทคโนโลยีเป็นสองด้านคือ การเก็บข้อมูล (Storage) และการประมวลผล/วิเคราะห์ข้อมูล (Process/Analytics) เราอาจสามารถจำแนกเทคโนโลยีต่างๆได้ดังนี้
เทคโนโลยีการเก็บข้อมูล
ข้อมูลที่เป็น Big Data อาจจะมีขนาดใหญ่เกินกว่าที่เทคโนโลยีการเก็บข้อมูลแบบเดิมที่เรามีอยู่เก็บได้หรืออาจเจอปัญหาในแง่โครงสร้างของข้อมูลที่อาจไม่เหมาะกับเทตโนโลยี RDBMS ตัวอย่างเช่น Telecom operator อาจต้องการเก็บข้อมูล Call Detail Records (CDR) ที่อาจมีปริมาณสูงถึง 1 TeraByte ต่อวันเป็นระยะเวลายาวนานขึ้น หรือเราอาจต้องเก็บข้อมูลในอีเมลจำนวนมากที่เป็นรูปแบบของ Text File หรือเก็บภาพจากกล้อง CCTV จำนวนหลายสิบ TB หรืออาจต้องการเก็บข้อมูลจาก Facebook ซึ่งข้อมูลต่างๆเหล่านี้ที่กล่าวมา อาจไม่เหมาะกับเทคโนโลยีฐานข้อมูลแบบเดิม RDBMS ที่เป็น Vertical Scaling
จากที่กล่าวมาจึ่งได้มีการนำเทคโนโลยีต่างๆเข้ามาเพื่อที่จะให้เก็บข้อมูลได้มากขึ้น โดยมีเทคโนโลยีต่างๆอาทิเช่น
- ฐานข้อมูล RDBMS แบบเดิม ก็ยังเป็นเทคโนโลยีที่เหมาะสมที่สุดในการเก็บข้อมูลแบบ Structure แต่ถ้าข้อมูลมีขนาดใหญ่มากก็จะเจอปัญหาเรื่องต้นทุนที่สูง และหากข้อมูลมีจำนวนเป็น PetaByte ก็คงยากที่จะเก็บ ถึงแม้ในปัจจุบันจะมี MPP Datanbase อย่าง Oracle ExaDta หรือ SAP HANA แต่ราคาก็สุงมาก
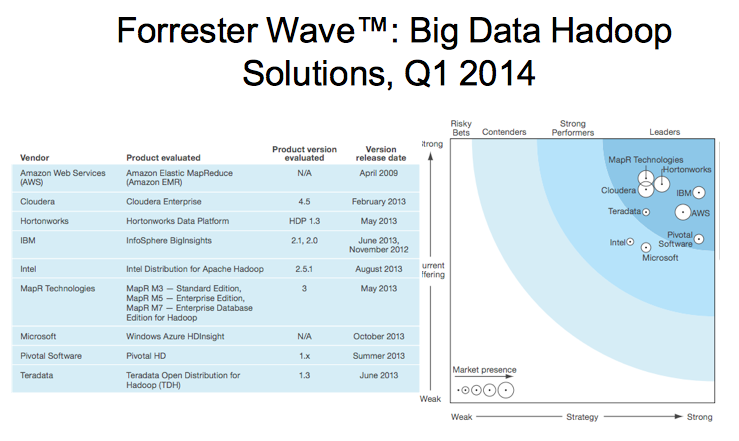
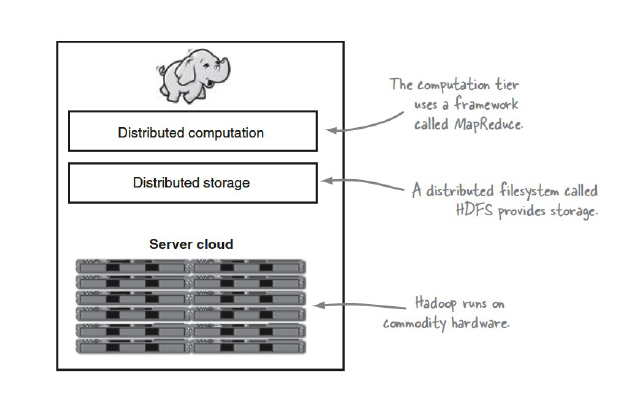
- Hadoop HDFS เป็นเทคโนโลยีที่มีการคาดการณ์ว่าหน่วยงานส่วนใหญ่จะต้องใช้ในอนาคต เพราะมีความต้องการเก็บข้อมูลขนาดใหญ่ทั้งที่เป็น Unstrucure Data หรือนำข้อมูลที่เป็น structure มาเก็บไว้ โดยสามารถจะเก็บข้อมูลได้เป็น PetaByte ทั้งนี้ขึ้นอยู่กับจำนวนเครื่องที่มีอยู่ในลักษณะ scale-out ข้อสำคัญ Hadoop มีต้นทุนที่ค่อนข้างต่ำเมื่อเทียบกับเทคโนโลยีการเก็บข้อมูลแบบอื่น ดังแสดงในรูปที่ 2
- NoSQL เป็นเทคโนโลยีที่ต้องการเก็บข้อมูลจำนวนมากกว่าของ RDBMS ในลักษณะ scale-out เป็นจำนวนหลาย TeraByte แต่อาจไม่ได้เน้นเรื่อง Consistency หรือ ACID ของข้อมูลมากนัก เหมาะกับ Application บางประเภท ทั้งนี้เราสามารถจะแบ่งเทคโนโลยี NoSQL ออกไปได้สี่กลุ่มคือ Column Oriented, Document Oriented, Key-Value และ Graph
- Cloud Storage ข้อมูลขนาดใหญ่ขององค์กรบางส่วนอาจต้องเก็บไว้ใน Public Cloud Storage เช่น Amazon S3 โดยเฉพาะข้อมูลภายนอกอาทิเช่น Social Media Data หรือข้อมูลที่เป็น Archiving ที่ไม่ได้มีความสำคัญมาก เพราะ Cloud Storage จะมีราคาในการเก็บที่ถูกสุด และสามารถที่จะเก็บได้โดยมีขนาดไม่จำกัด แต่ข้อเสียคือเรื่องความปลอดภัยและความเร็วในการถ่ายโอนข้อมูล

รูปที่ 2 เปรียบเทียบราคาของ Storage Technology
เทคโนโลยีการประมวลผลข้อมูล
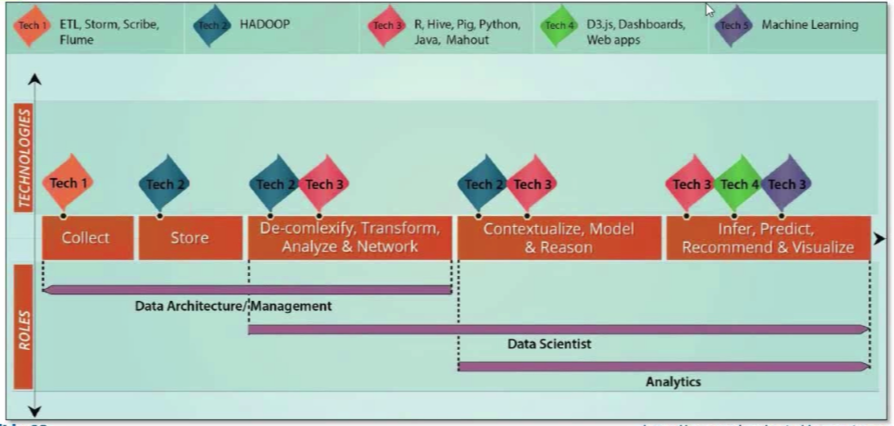
การประมวลผลข้อมูลที่เป็น Big Data จะมีทั้งการวิเคราะห์ข้อมูลที่เป็น business intelligence (BI) เพื่อที่จะดึงข้อมูลมานำเสนอ หรือการทำ Predictive Analytics โดยใช้หลักการของ Data Science ความยากของการประมวลผลคือต้องการความเร็วในการประมวลผลข้อมูลที่นอกจากมีขนาดใหญ่แล้วบางครั้งยังเป็นข้อมูลที่ไม่มีโครงสร้าง ดังนั้นต้องจึงมีการนำเทคโนโลยีหรือภาษาต่างๆมาเพื่อให้สามารถประมวลผลข้อมูลได้ ซึ่งในบางครั้งหน่วยงานอาจต้องพิจารณาต้องเลือกใช้ อาทิเช่น
- SQL ก็เป็นภาษาที่ยังต้องใช้ในการประมวลผลข้อมูลโดยเฉพาะ Structure Data ที่เก็บอยู่ใน RDBMS และสามารถประมวลผลแบบ RealTime ได้
- APIs ข้อมูลที่เก็บอยู่ใน Storage ต่างๆที่กล่าวมาข้างต้นเช่น NoSQL หรือ Cloud Storage อาจต้องพัฒนาโปรแกรมด้วยภาษาคอมพิวเตอร์ต่างๆ ในการประมวลผลข้อมูลโดยใช้ APIs ในการเข้าถึงข้อมูล
- MapReduce เป็นเทคโนโลยีที่พัฒนาโดย Google ในการประมวลผลข้อมูลที่อยู่ใน HDFS โดยใช้ภาษาคอมพิวเตอร์อย่าง Java ในการพัฒนาโปรแกรม โดยจะประมวลผลแบบ Batch และเป็นวิธีการประมวลผลที่มากับเทคโนโลยี Hadoop
- Hive หรือ Pig เป็นภาษาคล้าย SQL หรือ Scripting ที่ทำให้เราสามารถประมวลผลข้อมูลที่อยู่ใน Hadoop HDFS ได้โดยไม่ต้องพัฒนาโปรแกรม MapReduce แต่ทั้งนี้ข้อมูลจะต้องอยู่ในรูปแบบที่เหมาะสมเช่น ไฟล์ csv หรือ ไฟล์ข้อความบางประเภท
- Impala เป็นภาษาคล้าย SQL ที่ทำให้เราสามารถประมวลผลข้อมูลที่อยู่ใน Hadoop HDFS ได้ โดยทำงานได้รวดเร็วกว่า Hive มาก แต่มีข้อเสียคือเป็นภาษาที่เป็น proprietary ของ Cloudera
- Spark เป็นเทคโนโลยีที่สามารถประมวลผลข้อมูลขนาดใหญ่แบบ Real-time โดยอาจมี Data Source มาจากหลากหลายแหล่งเช่น RDBMS, Cloud Storage, NoSQL หรือ Hadoop ซึ่งสามารถเขียนโปรแกรมโดยใช้ภาษา Scala, Java, Python หรือจะเขียนโดยใช้ภาษาคล้าย SQL ก็ได้ และมี Library สำหรับการทำ Data Science คือ MLib เป็นเทคโนโลยีที่น่าสนใจมากอันหนึ่ง
- ภาษาและเทคโนโลยีในการทำ Machine Learning ซึ่งก็จะมีหลากหลายทั้ง R Hadoop, Mahout, Azure Machine Learning หรือ AWS ML
- เทคโนโลยีสำหรับการทำ Data Visualisation และ BI อาทิเช่น Tableau, Pentaho, SaS, Excel และอื่นๆ
จากที่กล่าวมาทั้งหมดนี้ ถ้าหน่วยงานจะมีโครงการ Big Data และข้อมูลมีขนาดใหญ่จริง เราคงต้องเลือกหาเทคโนโลยีที่เหมาะสมมาใช้งาน
ธนชาติ นุ่มนนท์
IMC Institute
สิงหาคม 2558