ผมเริ่มสนใจเรื่อง Big Data มาได้ซักพักหนึ่ง และโชคดีที่มีโอกาสได้อ่านหนังสือหลายเล่ม เรียนรู้ทั้งจาก Online Courseware ต่างๆทั้งที่ฟรีและเสียเงิน จริงๆท่านหนึ่งที่ต้องขอบคุณอย่างมากคือ คุณดนัยรัฐ ธนบดีธรรมจารี จาก Oracle ที่ได้มาช่วยสอนและแนะนำการติดตั้ง Hadoop ทำให้ผมได้เริ่มลงมือปฎิบัติในเรื่องของ Big Data มากขึ้นไม่ใช่แค่อ่านแต่หนังสือ ซึ่งก็ได้ศึกษา Hadoop และ Big Data มาอย่างต่อเนื่อง ทั้งการใช้เครื่องมือต่าง การใช้ Big Data as a Service บน Cloud เช่น Amazon Elastic Map Reduce การเรียนรู้ภาษาหรือ Tool ต่างๆเช่น Hive, Pig, HBase, Hue หรือ Mahout รวมถึงการอ่านหนังสืออีกหลายสิบเล่ม ลองมาดูกันครับว่ามีแหล่งข้อมูลไหนบ้างครับสำหรับการศึกษา Big Data และ Hadoop
Online Courseware
มีเว็บไซต์ดีๆหลายอันที่สอนเรื่อง Big Data โดยเฉพาะเรื่องของ Hadoop อาทิเช่น
- www.bigdatauniversity.com : ซึ่งเป็นเว็บไซต์การเรียนรู้ Big Data ของ IBM จะมี Courseware ดีๆอยู่หลายหลักสูตรที่มีทั้ง Slide เสียงบรรยาย และ Hand-on Lab อาทิเช่น Big Data Fundamentals, Hadoop Fundamentals หรือ Course ที่เรียนรู้เครื่องมือบางอย่างเช่น Moving Data into Hadoop แต่อย่างไรก็ตาม Hand-on Lab ใน courseware เหล่านี้จะผูกอยู่กับ IBM Infosphere BigInsight
- Cloudera Online Training: Cloudera เป็นบริษัทที่เด่นที่สุดบริษัทหนึ่งในการทำ Hadoop Distribution ส่วนหนึ่งก็เป็นเพราะว่าคนที่เริ่มคิดโปรเจ็ค Hadoop อยู่ที่บริษัทนี้ Cloudera จะมี Online Courseware ดีๆหลายตัว อาทิเช่น Introduction to Hadoop and MapReduce นอกจากนี้ยังมี Hand-on Training ซึ่งใช้เครื่องมือของ Cloudera Live ที่อยู่บน Cloud ให้สามารถฝึกและเรียนรู้การใช้เครื่องมือต่างๆอย่าง Pig หรือ Hive ได้
- Simplilearn: ในปัจจุบันมี Courseware ที่ผู้เรียนสามารถจ่ายเงินเรียน Online ได้หลายๆหลักสูตร ผมเองเคยเรียนหลักสูตรของ Simplilearn ที่ค่าเรียนประมาณร้อยกว่าเหรียญ เนื้อหาก็ดีพอควรสำหรับผู้สนใจเรีิ่มต่้นการทำ Big Data โดยใช้ Hadoop พร้อมทั้งมีแบบฝึกหัดให้ทำ

หนังสือด้าน Big Data
มีหนังสือหลายเล่มมากที่เกี่ยวข้องกับ Big Data ที่ผมมีโอกาสอ่าน ที่ได้อ่านหลายเล่มเป็นเพราะผมเป็นสมาชิก Safari Book Online ทำให้สามารถค้นหนังสือมาอ่านได้จำนวนมาก แต่บางเล่มก็ซื้อมาอ่านใน Kindle หนังสือต่างๆที่ผมอยากแนะนำมีดังนี้

Big Data: Understanding How Data Powers Big Business หนังสือเล่มนี้เหมาะกับผู้บริหารที่ต้องการทำความเข้าใจเกี่ยวกับ Big Data ซึ่งไม่ได้ต้องการลงด้านเทคนิคมากนัก หนังสือเล่มนี้จะให้คำตอบความหมายของ Big Data ผลกระทบต่อธุรกิจ การวางแผนกลยุทธ์ Big Data สำหรับองค์กร การกำหนดทีมงาน และการวางแผนต่างๆ นับเป็นหนังสือที่ดีมากสำหรับผู้บริหารที่ต้องการทำความเข้าใจและวางแผน Big Data ขององค์กร
Big Data Analytics: Turning Big Data into Big Money: เป็นหนังสืออีกเล่มสำหรับผู้บริหาร โดยจะกล่าวถึงความหมายของ Big Data พูดถึง Business Case การสร้าง Big Data Team การหา Big Data Source และอื่นๆ ผมว่าหนังสือเล่มนี้อ่านง่ายกว่าเล่มแรก แต่เล่มแรกจะมีทฤษฎีและ template ต่างๆ ให้เรานำไปใช้ได้ดีกว่า
Planning for Big Data: หนังสืออีกเล่มหนึ่งที่เป็นการกล่าวถึง Big Data ในลักษณะ High Level หนังสือออกมาเมื่อปี 2012 ซึ่งน่าจะอิงกับ Microsoft พอสมควร แต่ข้อดีคือเป็นหนังสือที่สามารถหาอ่านได้ฟรีทาง Amazon Kindle ในหนังสือจะพูดถึงความหมายของ Big Data, Apache Hadoop, Big Data Market Survey, Big Data in the Cloud และจะมีบทหนึ่งพูดถึง Microsoft’s Plan for Big Data
Hadoop Real-World Solutions Cookbook: หนังสือเล่มนี้เหมาะสำหรับนักไอทีที่ต้องการเรียน Hadoop และโปรแกรมอื่นๆที่เกี่ยวข้องของ Hadoop จะมีบทที่แนะนำ Hadoop และองค์ประกอบอื่นๆเช่น HDFS, MapReduce, Hive และ Pig หนังสือเล่มนี้จะมีเนื้อหาที่ดีในการแนะนำการเขียนโปรแกรม MapReduce โดยใช้ภาษา Java และมีตัวอย่างทีดีในการเขียนโปรแกรมโดยเฉพาะในบทที่ 6 ที่ว่าด้วยเรื่อง Big Data Analysis
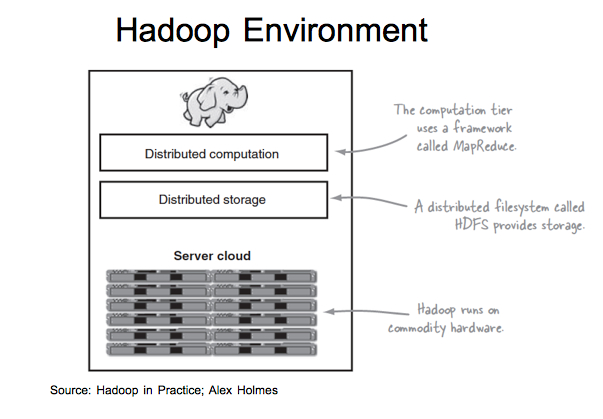
Hadoop in Practice: หนังสือด้่านเทคนิคอีกเล่มหนึ่งที่ค่อนข้างจะละเอียด และอาจจะอ่านยากกว่าเล่มก่อนหน้านี้ เหมาะสำหรับ Programmer ที่เข้าใจ command line ของ Linux เนื้อหาข้างในละเอียดมาก จุดเด่นของหนังสือเล่มนี้คือส่วนที่ 4 ที่กล่าวถึง Data Science และจะมีบทที่พูดถึง Algorithm ตัวอย่างการใช้ R และ Mahout
Hadoop: The Definitive Guide: หนังสืออีกเล่มที่แนะนำ Hadoop หนังสือเล่มนี้จะแนะนำซอฟต์แวร์ต่างๆของ Hadoop ไว้ได้ครอบคลุมทั้งหมดตั้งแต่ Hive, Pig, Sqoop, HBase หรือ Zookeeper รวมถึงพูดถึงการติดตั้ง Hadoop Cluster เล่มนี้เหมาะสำหรับ Administor ที่ต้องการติดตั้งและเข้าใจ Hadoop แต่ก็มีการกล่าวถึงการโปรแกรม MapReduce อยู่หลายบทเหมือนกัน
Programming Hive: หนังสือเล่มนี้สำหรับผู้สนใจจะใช้คำสั่งคล้าย SQL บน Hadoop เพื่อที่จะสืบค้นข้อมูล Unstructure โดยใช้โปรแกรม Hive หนังสือเหมาะกับผู้ที่สนใจเล่น Hive อย่างจริงจัง เพราะมีหลายละเอียดค่อนข้างมากตั้งแต่ Data Types การใช้ภาษา Hive QL ผมเองได้แค่อ่านผ่านๆเพราะไม่ได้ต้องการเจาะลึกการใช้ Hive
Mahout in Action: หนังสือนี้เหมาะกับ Data Scientist ที่ต้องการพัฒนา Scalable Machine Learning โดยใช้ Mahout ที่รันอยู่บน Hadoop หนังสือเล่มนี้จะอ่านยากมากเพราะจะเต็มไปด้วยสูตรคณิตศาสตร์ต่างๆและโปรแกรมภาษาจาวาโดยใช้ Mahout หนังสือจะกล่าวถึงการทำ Preditive Analysis สามเรื่องที่ Mahout สามารถทำได้คือ Recommendation, Classification และ Clustering
ธนชาติ นุ่มนนท์
IMC Institute
ตุลาคม 2557